Debezium Architecture
Most commonly, you deploy Debezium by means of Apache Kafka Connect. Kafka Connect is a framework and runtime for implementing and operating:
-
Source connectors such as Debezium that send records into Kafka
-
Sink connectors that propagate records from Kafka topics to other systems
The following image shows the architecture of a change data capture pipeline based on Debezium:
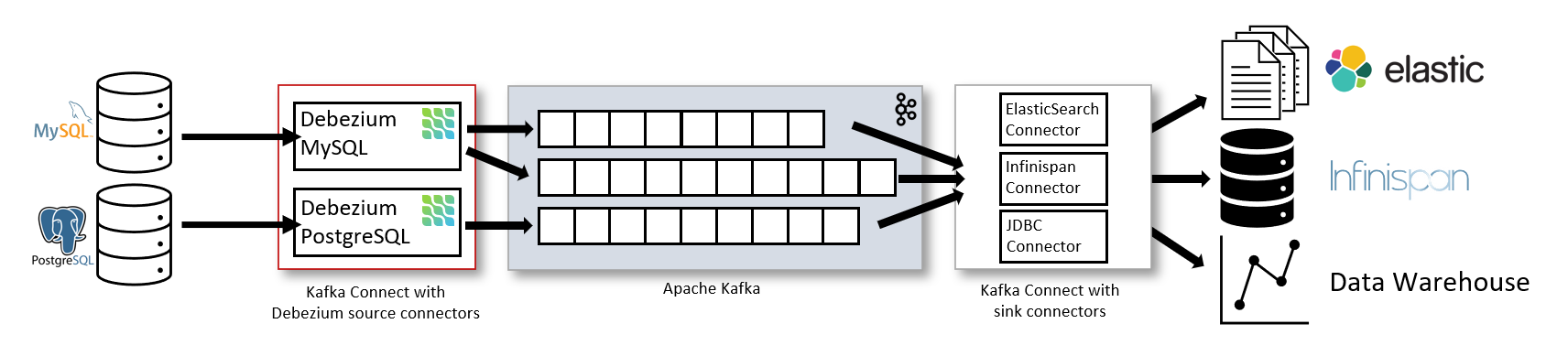
As shown in the image, the Debezium connectors for MySQL and PostgresSQL are deployed to capture changes to these two types of databases. Each Debezium connector establishes a connection to its source database:
-
The MySQL connector uses a client library for accessing the
binlog. -
The PostgreSQL connector reads from a logical replication stream.
Kafka Connect operates as a separate service besides the Kafka broker.
By default, changes from one database table are written to a Kafka topic whose name corresponds to the table name. If needed, you can adjust the destination topic name by configuring Debezium’s topic routing transformation. For example, you can:
-
Route records to a topic whose name is different from the table’s name
-
Stream change event records for multiple tables into a single topic
After change event records are in Apache Kafka, different connectors in the Kafka Connect eco-system can stream the records to other systems and databases such as Elasticsearch, data warehouses and analytics systems, or caches such as Infinispan.
Depending on the chosen sink connector, you might need to configure Debezium’s new record state extraction transformation. This Kafka Connect SMT propagates the after structure from Debezium’s change event to the sink connector. This is in place of the verbose change event record that is propagated by default.
Embedded Engine
An alternative way for using the Debezium connectors is the embedded engine. In this case, Debezium will not be run via Kafka Connect, but as a library embedded into your custom Java applications. This can be useful for either consuming change events within your application itself, without the needed for deploying complete Kafka and Kafka Connect clusters, or for streaming changes to alternative messaging brokers such as Amazon Kinesis. You can find an example for the latter in the examples repository.