
The engineering team at Shopify recently improved the Debezium MySQL connector so that it supports incremental snapshotting for databases without write access by the connector, which is required when pointing Debezium to read-only replicas. In addition, the Debezium MySQL connector now also allows schema changes during an incremental snapshot. This blog post explains the implementation details of those features.
Why read-only?
Debezium added the incremental snapshotting feature in the 1.6 release, after Netflix had announced their change data capture framework. At Shopify, we use Debezium for change data capture (CDC), and we were looking forward to being the early adopters. Besides, we wished to have a solution that is writes and locks-free.
The no writes solution allows to capture changes from read-replicas and provides the highest guarantee that CDC won’t cause data corruption on the database side.
We’ve had to coordinate the snapshotting with migrations in the past since schema migrations blockades have affected other projects' development. The solution was to run snapshots only on weekends and as a result, we tried to snapshot as rarely as possible. We saw the opportunity to improve this part of the process as well.
This blog post dives into technical details of the read-only incremental snapshots implementation including lock-free schema changes handling during the incremental snapshot in MySQL connector.
Incremental snapshots
The Incremental Snapshots in Debezium blog post covers the default implementation in detail. The algorithm utilizes a signaling table for two types of signals:
-
snapshot-window-open/snapshot-window-closeas watermarks -
execute-snapshotas a way to trigger an incremental snapshot
For the read-only scenario, we needed to replace both types of signals with alternatives.
SHOW MASTER STATUS for high and low watermarks
The solution is specific to MySQL and relies on global transaction identifiers (GTIDs). Therefore, you need to set gtid_mode to ON and configure the database to preserve GTID ordering if you’re reading from the read replica.
Prerequisites:
gtid_mode = ON
enforce_gtid_consistency = ON
if replica_parallel_workers > 0 set replica_preserve_commit_order = ONThe algorithm runs a SHOW MASTER STATUS query to get the executed GTID set before and after the chunk selection:
low watermark = executed_gtid_set
high watermark = executed_gtid_set - low watermarkIn the read-only implementation, the watermarks have a form of GTID sets, e.g. like this:
2174B383-5441-11E8-B90A-C80AA9429562:1-3, 24DA167-0C0C-11E8-8442-00059A3C7B00:1-19
Such watermarks do not appear in the binlog stream. Instead, the algorithm compares each event’s GTID against the in-memory watermarks. The implementation ensures there are no stale reads and that a chunk only has changes that are not older than events up to low watermark.
Deduplication algorithm with read-only watermarks
In pseudo-code, the algorithm for deduplicating events read from the binlog and events retrieved via snapshot chunks looks like this:
(1) pause log event processing
(2) GtidSet lwGtidSet := executed_gtid_set from SHOW MASTER STATUS
(3) chunk := select next chunk from table
(4) GtidSet hwGtidSet := executed_gtid_set from SHOW MASTER STATUS subtracted by lwGtidSet
(5) resume log event processing
inwindow := false
// other steps of event processing loop
while true do
e := next event from changelog
append e to outputbuffer
if not inwindow then
if not lwGtidSet.contains(e.gtid) //reached the low watermark
inwindow := true
else
if hwGtidSet.contains(e.gtid) //haven't reached the high watermark yet
if chunk contains e.key then
remove e.key from chunk
else //reached the high watermark
for each row in chunk do
append row to outputbuffer
// other steps of event processing loopWatermark checks
A database transaction can change several rows. In this case, multiple binlog events will have the same GTID. Due to GTIDs not being unique, it affects the logic of computing a chunk selection window. An event updates a window state when the watermark’s GTID set doesn’t contain its GTID. After the events like transaction completion and heartbeat, there won’t be any further binlog events with the same GTID. For those events, it’s enough to reach the watermark’s upper bound to trigger a window open/close.
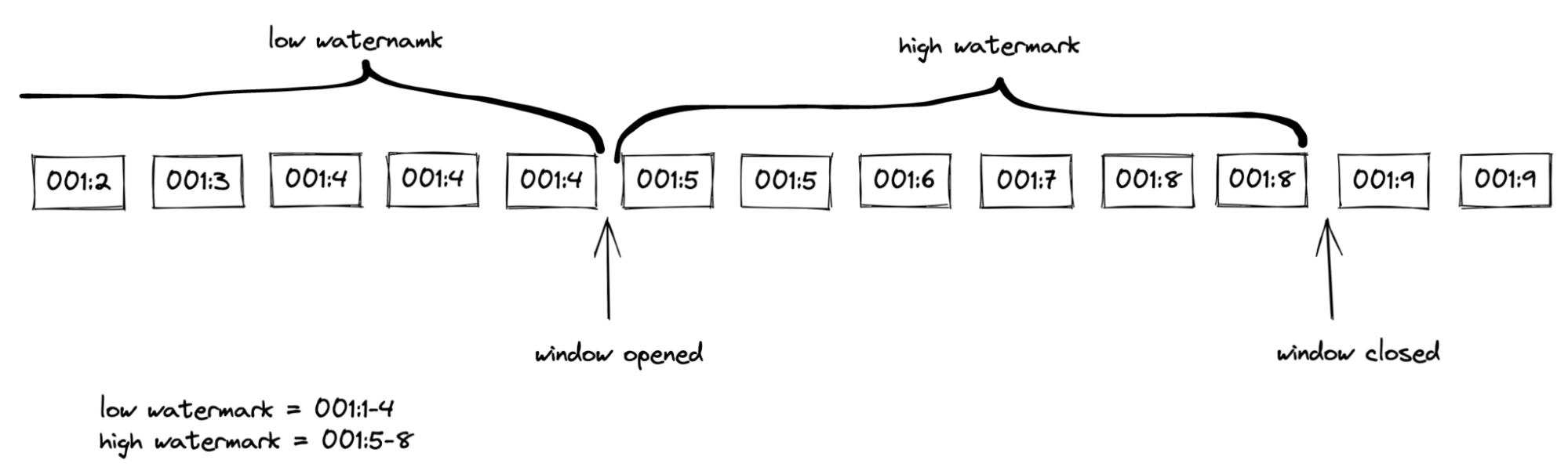
Figure 1. A chunk selection window
The deduplication happens within the chunk selection window as in the default implementation. Finally, the algorithm inserts a deduplicated chunk right after the high watermark:
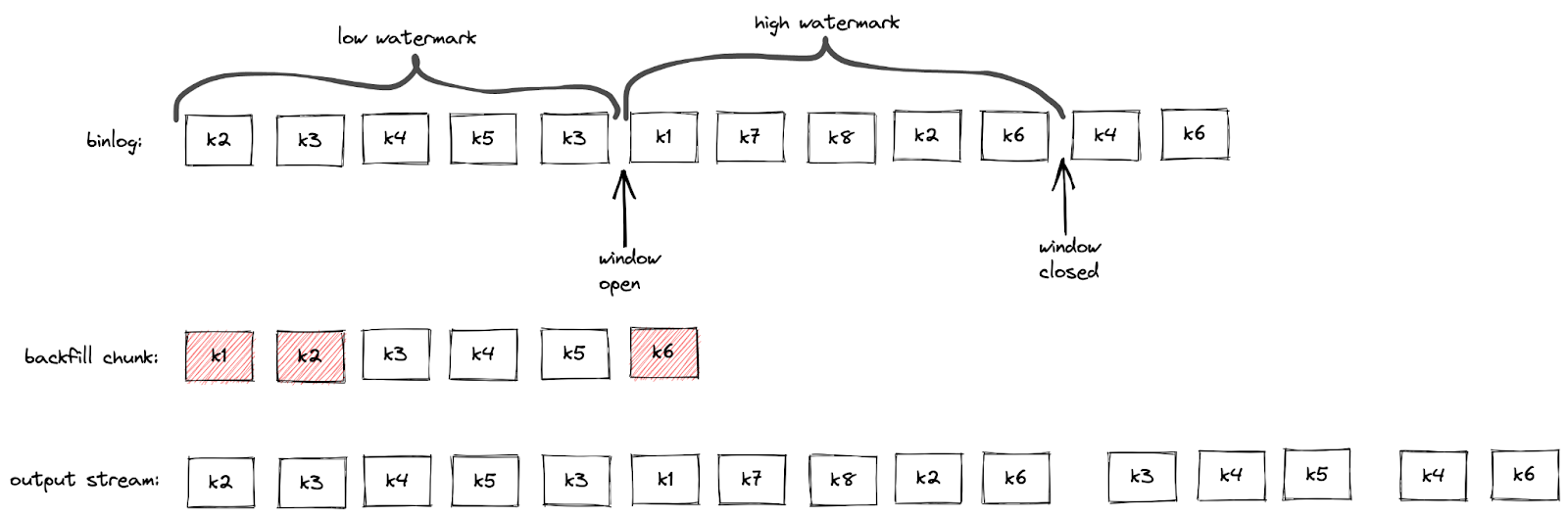
Figure 2. A chunk deduplication
No updates for included tables
It’s crucial to receive binlog events for the snapshot to make progress. So the algorithm checks GTIDs of all the events together with not included tables.
No binlog events
The MySQL server sends a heartbeat event after the replication connection was idle for x-seconds. The read-only implementation utilizes heartbeats when the rate of binlog updates is low.
The heartbeat has the same GTID as the latest binlog event. Thus, for a heartbeat, it’s enough to reach the upper bound of the high watermark.
The algorithm uses the server_uuid part of a heartbeat’s GTID to get the max transaction id from the high watermark. The implementation makes sure the high watermark contains a single server_uuid. An unchanged server_uuid allows to avoid the scenario when the window is closed too early by a heartbeat. See the image below as an example:
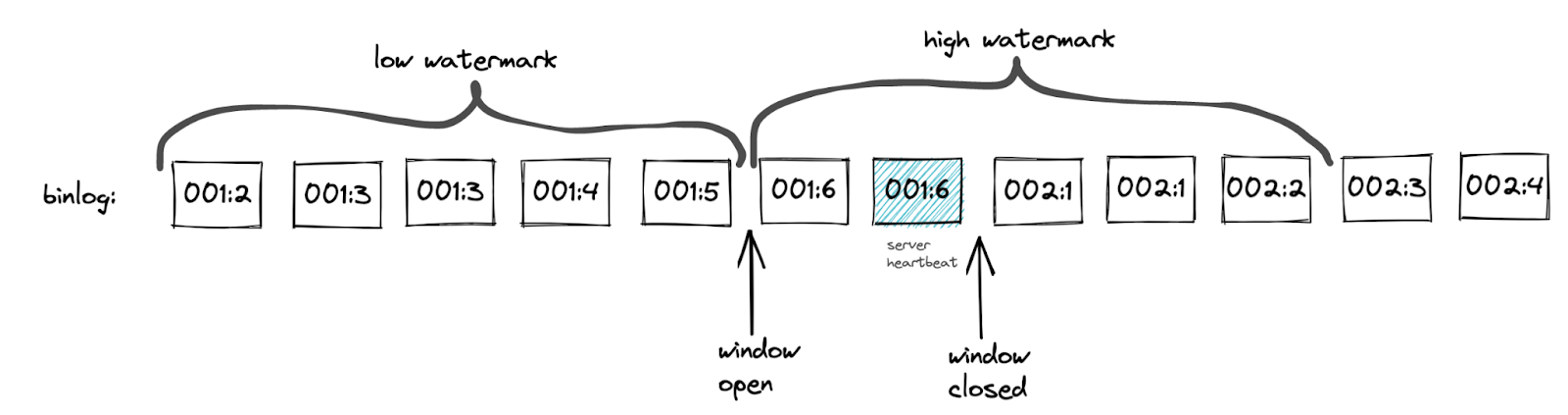
Figure 3. A scenario when the window would have been closed too early by a heartbeat
A heartbeat comparison against the low watermark isn’t needed since it doesn’t matter if the window was open or not. This simplifies the checks when there are no new events between the high and low watermarks.
No changes between watermarks
A binlog event can open and close a window right away when there were no binlog events during the chunk selection. In this case, a high watermark will be an empty set. In this case, the snapshot chunk gets inserted right after the low watermark without deduplication.
Figure 4. An empty chunk selection window
Kafka topic based signals
Debezium supports ad-hoc incremental snapshots triggered via inserts to the signaling table. A read-only alternative is to send signals through a specific Kafka topic. The format of the message mimics the signaling table structure. An execute-snapshot Kafka message includes the parameters
-
data-collections- list of tables to be captured -
type- set to INCREMENTAL
Example:
Key: dbserver1
Value: {"type":"execute-snapshot","data": {"data-collections": ["inventory.orders"], "type": "INCREMENTAL"}}The MySQL connector’s config has a new signal.kafka.topic property. The topic has to have one partition and the delete retention policy.
A separate thread retrieves the signal messages from the Kafka topic. The key of the Kafka message needs to match the connector’s name as set in database.server.name. The connector will skip events that don’t correspond to the connector’s name with a log entry. The message key check allows reusing a signal topic for multiple connectors.
The connector’s offsets include incremental snapshot context when an incremental snapshot is running. The read-only implementation adds the Kafka signal offset to the incremental snapshot context. Keeping track of the offset allows it not to miss or double process the signal when the connector restarts.
However, it’s not required to use Kafka to execute a read-only incremental snapshot and the default execute-snapshot signal written into a signaling table will also work.
Going forward, a REST API for triggering ad-hoc incremental snapshots may be envisioned as well,
either exposed through Debezium Server, or as an additional REST resource deployed to Kafka Connect.
Schema changes during incremental snapshots
The Debezium MySQL connector allows schema changes during an incremental snapshot. The connector will detect schema change during an incremental snapshot and re-select a current chunk to avoid locking DDLs.
Note that changes to a primary key are not supported and can cause incorrect results if performed during an incremental snapshot.
Historized Debezium connectors like the MySQL one parse Data Definition Language (DDL) events such as ALTER TABLE from the binlog stream. Connectors keep an in-memory representation of each table’s schema and use those schemas to produce the appropriate change events.
The incremental snapshot implementation uses binlog schema twice:
-
at the moment of the chunk selection from the database
-
at the moment of the chunk insertion to the binlog stream
The chunk’s schema has to match the binlog schema at both times. Let’s explore how the algorithm achieves matching schemas in detail.
Matching chunk and binlog schema on selection
When the incremental snapshot queries a database, the rows have the table’s latest schema. If the binlog stream is behind, the in-memory schema may be different from the latest schema. The solution is to wait for the connector to receive the DDL event in the binlog stream. After that, the connector can use the cached table’s structure to produce the correct incremental snapshot events.
A snapshot chunk is selected using the JDBC API. ResultSetMetaData stores the chunk’s schema. The challenge is that the schema from ResultSetMetaData and the schema from binlog DDL have different formats, making it hard to determine if they are identical.
The algorithm uses two steps to obtain the matching ResultSet-based and DDL-based schemas. First, the connector queries a table’s schema between low and high watermarks. As soon as the connector detects the window closure, the binlog schema is up to date with the ResultSetMetaData. After that, the connector queries the database to verify that the schema remains the same. If the schema has changed, then the connector repeats the process.
The algorithm keeps the matching ResultSet and binlog schemas in memory to allow the connector to compare each chunk’s schema against the cached ResultSet schema.
When a chunk’s schema doesn’t match the cached ResultSet schema, the connector drops the selected chunk. Then the algorithm repeats the verification process of matching ResultSet and binlog schemas. After that, the connector re-selects the same chunk from the database:
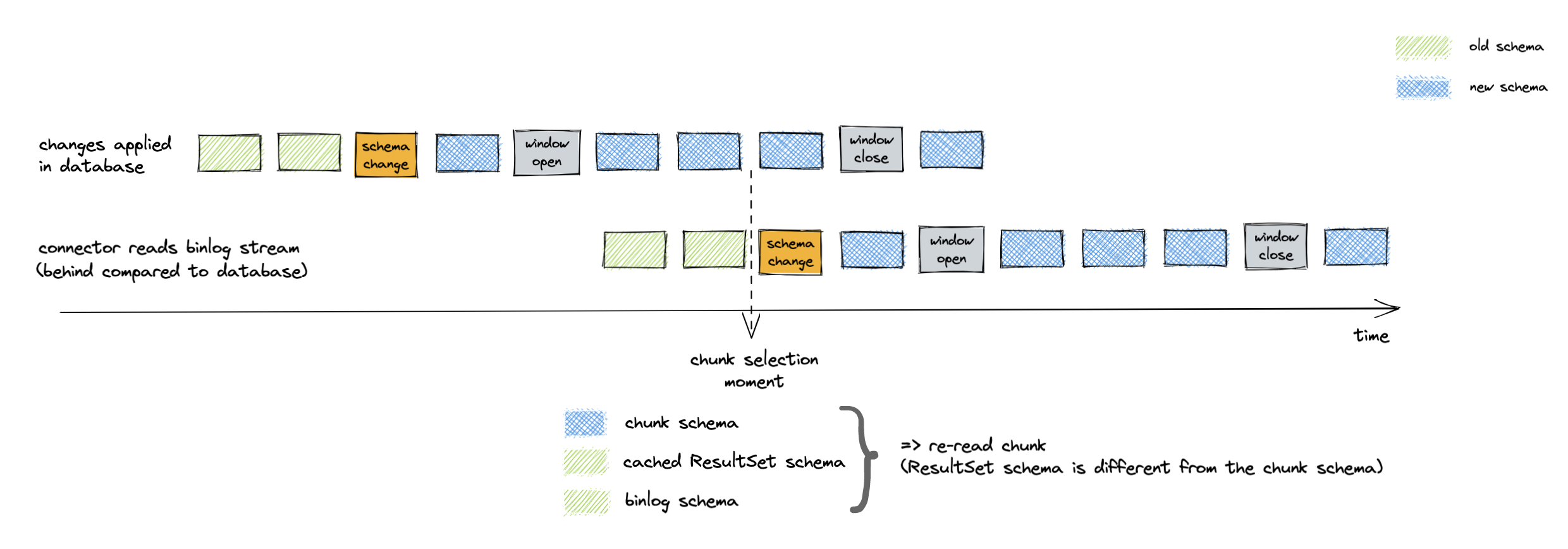
Figure 5. Binlog schema doesn’t match chunk schema on chunk selection
Matching chunk and binlog schema on insertion
A DDL event also triggers a chunk re-read for the affected table. A re-read prevents a scenario when a chunk has an older schema than the binlog stream has by the window closure. For example, the picture below illustrates the chunk selection that happened before the schema change:
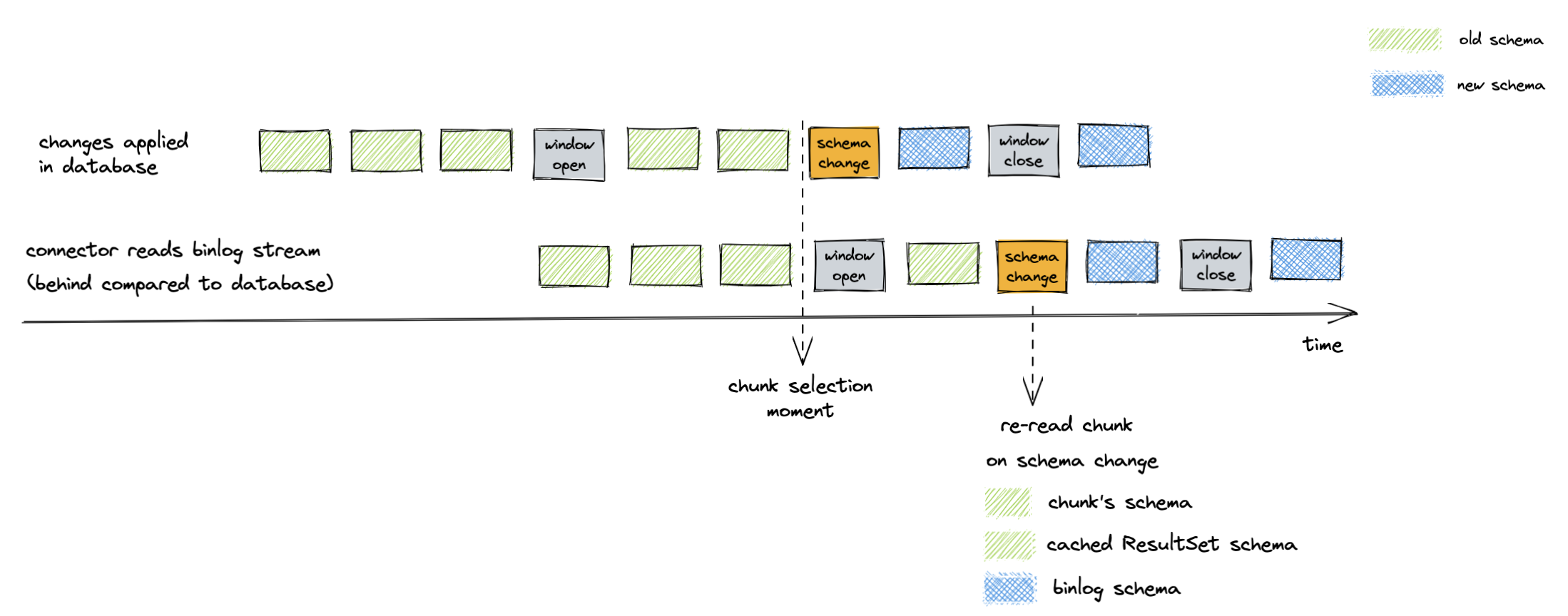
Figure 6. Binlog schema doesn’t match chunk schema on chunk insertion
Demo
We will use the standard tutorial deployment to demonstrate read-only ad-hoc incremental snapshotting. We are using MySQL as the source database. For this demo, you will need to open multiple terminal windows.
In the beginning we will start the deployment, create the signaling Kafka topic, and start the connector:
# Terminal 1 - start the deployment
# Start the deployment
export DEBEZIUM_VERSION=1.9
docker-compose -f docker-compose-mysql.yaml up
# Terminal 2
# Enable enforce_gtid_consistency and gtid_mode
docker-compose -f docker-compose-mysql.yaml exec mysql bash -c 'mysql -p$MYSQL_ROOT_PASSWORD inventory -e "SET GLOBAL enforce_gtid_consistency=ON; SET GLOBAL gtid_mode=OFF_PERMISSIVE; SET GLOBAL gtid_mode=ON_PERMISSIVE; SET GLOBAL gtid_mode=ON;"'
# Confirm the changes
docker-compose -f docker-compose-mysql.yaml exec mysql bash -c 'mysql -p$MYSQL_ROOT_PASSWORD inventory -e "show global variables like \"%GTID%\";"'
# Create a signaling topic
docker-compose -f docker-compose-mysql.yaml exec kafka /kafka/bin/kafka-topics.sh \
--create \
--bootstrap-server kafka:9092 \
--partitions 1 \
--replication-factor 1 \
--topic dbz-signals
# Start MySQL connector, capture only customers table and enable signaling
curl -i -X POST -H "Accept:application/json" -H "Content-Type:application/json" http://localhost:8083/connectors/ -d @- <<EOF
{
"name": "inventory-connector",
"config": {
"connector.class": "io.debezium.connector.mysql.MySqlConnector",
"tasks.max": "1",
"database.hostname": "mysql",
"database.port": "3306",
"database.user": "debezium",
"database.password": "dbz",
"database.server.id": "184054",
"database.server.name": "dbserver1",
"database.include.list": "inventory",
"database.history.kafka.bootstrap.servers": "kafka:9092",
"database.history.kafka.topic": "schema-changes.inventory",
"table.include.list": "inventory.customers",
"read.only": "true",
"incremental.snapshot.allow.schema.changes": "true",
"incremental.snapshot.chunk.size": "5000",
"signal.kafka.topic": "dbz-signals",
"signal.kafka.bootstrap.servers": "kafka:9092"
}
}
EOFFrom the log we see that as per the table.include.list setting only one table is snapshotted, customers:
tutorial-connect-1 | 2022-02-21 04:30:03,936 INFO MySQL|dbserver1|snapshot Snapshotting contents of 1 tables while still in transaction [io.debezium.relational.RelationalSnapshotChangeEventSource]
In the next step we will simulate continuous activity in the database:
# Terminal 3
# Continuously consume messages from Debezium topic for customers table
docker-compose -f docker-compose-mysql.yaml exec kafka /kafka/bin/kafka-console-consumer.sh \
--bootstrap-server kafka:9092 \
--from-beginning \
--property print.key=true \
--topic dbserver1.inventory.customers
# Terminal 4
# Modify records in the database via MySQL client
docker-compose -f docker-compose-mysql.yaml exec mysql bash -c 'i=0; while true; do mysql -u $MYSQL_USER -p$MYSQL_PASSWORD inventory -e "INSERT INTO customers VALUES(default, \"name$i\", \"surname$i\", \"email$i\");"; ((i++)); done'The topic dbserver1.inventory.customers receives a continuous stream of messages. Now the connector will be reconfigured to also capture the orders table:
# Terminal 5
# Add orders table among the captured
curl -i -X PUT -H "Accept:application/json" -H "Content-Type:application/json" http://localhost:8083/connectors/inventory-connector/config -d @- <<EOF
{
"connector.class": "io.debezium.connector.mysql.MySqlConnector",
"tasks.max": "1",
"database.hostname": "mysql",
"database.port": "3306",
"database.user": "debezium",
"database.password": "dbz",
"database.server.id": "184054",
"database.server.name": "dbserver1",
"database.include.list": "inventory",
"database.history.kafka.bootstrap.servers": "kafka:9092",
"database.history.kafka.topic": "schema-changes.inventory",
"table.include.list": "inventory.customers,inventory.orders",
"read.only": "true",
"incremental.snapshot.allow.schema.changes": "true",
"incremental.snapshot.chunk.size": "5000",
"signal.kafka.topic": "dbz-signals",
"signal.kafka.bootstrap.servers": "kafka:9092"
}
EOF
As expected, there are no messages for the orders table:
# Terminal 5
docker-compose -f docker-compose-mysql.yaml exec kafka /kafka/bin/kafka-console-consumer.sh \
--bootstrap-server kafka:9092 \
--from-beginning \
--property print.key=true \
--topic dbserver1.inventory.ordersNow let’s start an incremental ad-hoc snapshot by sending a signal. The snapshot messages for the orders table are delivered to the dbserver1.inventory.orders topic. Messages for the customers table are delivered without interruption.
# Terminal 5
# Send the signal
docker-compose -f docker-compose-mysql.yaml exec kafka /kafka/bin/kafka-console-producer.sh \
--broker-list kafka:9092 \
--property "parse.key=true" \
--property "key.serializer=org.apache.kafka.common.serialization.StringSerializer" \
--property "value.serializer=custom.class.serialization.JsonSerializer" \
--property "key.separator=;" \
--topic dbz-signals
dbserver1;{"type":"execute-snapshot","data": {"data-collections": ["inventory.orders"], "type": "INCREMENTAL"}}
# Check messages for orders table
docker-compose -f docker-compose-mysql.yaml exec kafka /kafka/bin/kafka-console-consumer.sh \
--bootstrap-server kafka:9092 \
--from-beginning \
--property print.key=true \
--topic dbserver1.inventory.ordersIf you were to modify any record in the orders table while the snapshot is running, this would be either emitted as a read event or as an update event, depending on the exact timing and sequence of things.
As the last step, let’s terminate the deployed systems and close all terminals:
# Shut down the cluster
docker-compose -f docker-compose-mysql.yaml downConclusion
Debezium is an excellent change data capture tool under active development, and it’s a pleasure to be a part of its community. We’re excited to use incremental snapshots in production here at Shopify. If you have similar database usage restrictions, check out the read-only incremental snapshots feature. Many thanks to my team and the Debezium team without whom this project wouldn’t happen.
About Debezium
Debezium is an open source distributed platform that turns your existing databases into event streams, so applications can see and respond almost instantly to each committed row-level change in the databases. Debezium is built on top of Kafka and provides Kafka Connect compatible connectors that monitor specific database management systems. Debezium records the history of data changes in Kafka logs, so your application can be stopped and restarted at any time and can easily consume all of the events it missed while it was not running, ensuring that all events are processed correctly and completely. Debezium is open source under the Apache License, Version 2.0.
Get involved
We hope you find Debezium interesting and useful, and want to give it a try. Follow us on Twitter @debezium, chat with us on Zulip, or join our mailing list to talk with the community. All of the code is open source on GitHub, so build the code locally and help us improve ours existing connectors and add even more connectors. If you find problems or have ideas how we can improve Debezium, please let us know or log an issue.