
We have developed a Debezium connector for usage with Db2 which is now available as part of the Debezium incubator. Here we describe the use case we have for Change Data Capture (CDC), the various approaches that already exist in the Db2 ecology, and how we came to Debezium. In addition, we motivate the approach we took to implementing the Db2 Debezium connector.
Background: Bringing Data to a Datalake
In 2016 IBM started an effort to build a single platform on which IBM’s Enterprise Data could be ingested, managed and processed: the Cognitive Enterprise Data Platform (CEDP). IBM Research was one of the major contributors to this project. One of the fundamental activities was bringing data from geographically distributed data centers to the platform. The ingestion into the Datalake used a wide variety of technologies.
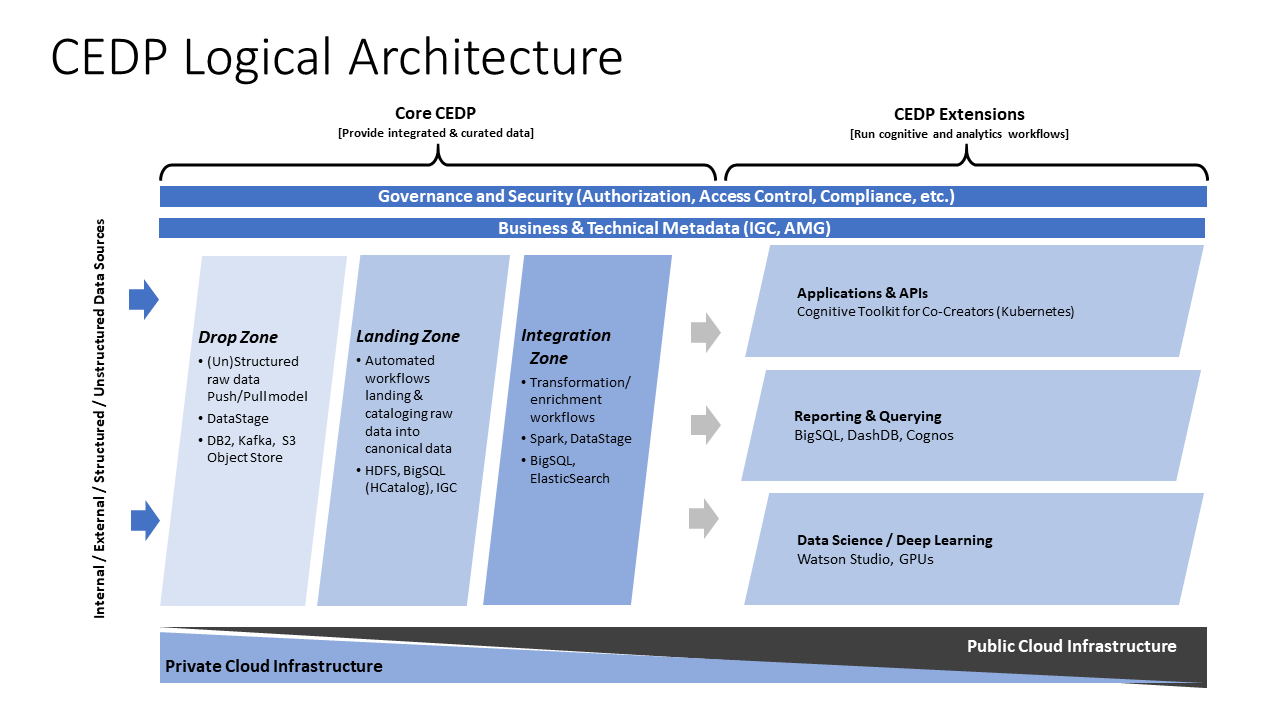
Figure 1. CEDP Logical Architecture
A significant fraction of this enterprise data is gathered in relational databases present in existing data-warehouses and datamarts. These are generally production systems whose primary usage is as "systems of record" for marketing, sales, human resources etc. As these are systems run by IBM for IBM unsurprisingly they are mainly some variant of IBM’s Db2.
Getting Data From Db2 Efficiently
Data is ingested into an immutable Landing Zone within the Datalake. This Landing Zone is implemented as a HDFS instance. Streaming data, e.g. news, is moved from the source using Kafka and then written into HDFS using the appropriate connector.
One of our key design objective is automation. There are over 5,000 relational database tables from over 200 different sources ingested every day. In order to scale the data processing platform - aside from the governance processes that allow data owners to bring data to the platform - the ingestion itself must be self-service.
Initially relational data was always bulk loaded from the source using Sqoop. A REST Interface is made available such that the data owners can configure when the data should be moved, e.g. periodically, trigger on event etc. A Sqoop ingestion is a distributed set of tasks each of which uses a JDBC connection to read part of a relational database table, generate a file based representation of the data, e.g. Parquet, and then store it on HDFS. With Sqoop we can completely refresh the data, or append to it, However we cannot modify the data incrementally.
From a practical point of view this limits the periodicity with which data can be updated. Some of the larger tables represent tens of GBytes of compressed Parquet. While Sqoop allows many tasks to be run in parallel for the same table the bottleneck is typically the network across the WAN and/or rate controlling at the source database system itself. Often only a small fraction of the table is modified on any particular day, meaning that a huge amount of data is sent unnecessarily.
To address these issues we introduced the use of Change Data Capture (CDC) for the movement of data across the WAN. Ingestion in CDC mode into a storage system designed for files that are never modified is problematic. While some recent work like Deltalakes or Hive 3.0 have started introducing delta changes into the Hadoop ecosystem, these were not mature enough for our needs.
As an alternative we use the concept of a Relational Database Drop Zone in which data owners can instantiate shadows of their database and from which we then ingest into HDFS. As the Drop Zone and Landing Zone are in the same data center and the ingesting of data is a highly parallelizable task, the actual ingestion of large tables was typically orders of magnitude faster than the transferring of the data from the source.
Data owners could move data using whatever tool they preferred into their Drop Zone. In particular they could transfer changes to data obtained through CDC.
CDC systems are almost as old as relational databases themselves. Typically these were designed for purposes of back-up or failure recovery and were designed for use by a database administrator.
Db2 has a long pedigree being over 40 years old and running on a wide set of operating systems including zOS, AIX, Linux and Windows. It has evolved a large set of distinct tools for CDC for uses in different contexts. We started exploring the use of IBM’s SQL Replication. Once tables are put into CDC mode by the admin, a capture agent is started that reads changes made to those tables from the transaction log. The changes are stored in dedicated CDC Tables. At the remote database an apply agent periodically reads the changes from these CDC tables and updates the shadow tables.
While conceptually this is quite simple in practice it is difficult to automate for the following reasons:
-
Source and sink are tightly coupled and therefore the same table cannot easily be replicated to multiple different target database systems.
-
If the source system was already using replication on a table e.g. for back-up purposes, we cannot use this method to replicate to the Datalake.
-
Elevated privileges are required on the source. Data owners give read access to their system for Sqoop, but giving administrator poses compliance problems.
-
Elevated privileges are required on the sink. For simplicity our Drop Zone is a single Db2 system with database instances for each of the data sources. Allowing the data owners to set up SQL Replication to the Drop Zone would allow them access to each other’s instances, which is a compliance violation.
-
The tools are designed for system admins and as a result there are a large number of gotchas for the unwary. For example, care must be taken in selecting a wide range of parameters such as: the mode that the transaction log has to be in to allow CDC, the time the last backup was taken, whether the database is row or column oriented etc.
-
It is a Db2-specific solution; although the majority of the relational data sources were Db2, we also had Netezza, MySQL and SQL Server sources.
We found in practice that the combination of the above meant that it was impractical to allow data owners to use IBM SQL Replication as a CDC mechanism for the Datalake.
IBM offers another set of tools for data replication called IBM InfoSphere Data Replication (IIDR). This is sold as a product distinct from Db2. IIDR is not a Db2 specific solution, working for a wide range of relational databases as well as non-relational data storage systems, e.g. file systems. In essence IIDR has source agents and sink agents. The source and sink agent run at or close to the target system. Source agents read the changes and propagate them via a wide range of protocols including TCP sockets, MQ, Shared Files etc. to the sink agent. The source and sink agents are configured via an entity called the Access Server through which sources are connected to sinks and the tables to capture are specified. The Access Server is itself typically controlled via a Graphical User Interface by a system administrator.
Thus for example we can have a Db2 source agent and an IIDR Kafka sink agent that behaves like a standard Apache Kafka Connect source connector, i.e. it writes change events into a Kafka topic. The initial records are Upsert messages (REFRESH phase) and subsequent changes are propagated as a sequence of Upsert/Delete Messages (MIRROR phase).
IIDR makes the system more loosely coupled and less Db2 specific. However, it is still not simple to automate. In essence we need to be able to allow a data owner to specify the source database system and the tables to replicate via a REST call and automatically configure and deploy the necessary agents and Access Server on our Kubernetes cluster. As we can not run on the source system itself we catalog the remote Db2 system to look like it was local and ran the agent on that.
IIDR assumes the agent runs on the same hardware architecture as the relational database system. The IIDR agent uses a low level Db2 API to read the transaction log. Many of our sources systems are running on AIX/PowerPC while the Kubernetes platform on which the agents are deployed runs on Linux/Intel. This leads to endianness compatibility problems.
There are two limitations to this approach:
-
IIDR is designed to be monitored and managed by a system administrator. Trying to capture the actions and responses of an administrator via scripts that parse these logs and attempt to react to failure in IIDR can only be brittle. As long as nothing misbehaves the system runs fine, but if something fails (network interruption, Kubernetes proxy failure, LDAP being down, etc.) it is almost impossible to automate the appropriate response.
-
While touching the source system as little as possible was an admirable objective, from a practical point of view it is almost impossible on a production system to run the CDC system independently of the source system. If a system admin reloads from back-up an older version of a table or radically changes the DDL of that table the CDC system must be aware that this has occurred and take the appropriate action. In the case of changing the DDL, a new version of the table is created and consequently a new version of the KTable in turn must be created.
We saw these and many more problems when trying to use the above approach for using CDC against real production systems. We concluded that the administration of the CDC system and the source system cannot be done independently and that to a large extent our problems came from trying to use IIDR for a use-case for which it was not intended.
Approaches to Implementing a Debezium Db2 Connector
When Debezium became available we started evaluating it for our purposes. As it works with a wide range of relational database systems and is open source we could imagine that database administrators would allow it to be used to generate a representation of their data for downstream applications. Essentially, the Debezium system would become an extension of the database source system. Debezium is not required to produce an identical copy of the database tables (unlike IIDR or SQL Replication). Typically the downstream application are for auxiliary tasks, i.e. analytics, not for fail over, meaning problems such as preserving precise types are less pressing. For example, if a time-stamp field is represented as a string in Elasticsearch it is not the end of the world.
The only concern we had with Debezium was that it didn’t have a connector for Db2.
Two approaches presented themselves:
-
Use the low level Db2 API to read directly the transaction log like IIDR does.
-
Use the SQL Replication CDC capture tables to read capture tables using SQL.
An investigation of the code concluded that the model used by the already existing connector for Microsoft SQL Server could be largely reused for Db2. In essence:
-
The SQL queries to poll the changes are different
-
The structure and nature of the Logical Sequence Number (LSN) are different
-
The fact that Db2 distinguishes between a database system and a database while SQL Server does not needs to be accounted for.
Otherwise everything else could be reused. Thus we adapted the existing SQL Server code base to implement the Db2 connector.
Future Work/Extensions
Benchmarking
The Connectors for Db2 and SQL Server use a polling model i.e. the connectors periodically query the CDC table to determine what has changed since the last time they polled. A natural question is what is the "optimal" polling frequency given the fact that polling itself has a cost, i.e. what are the trade-offs between latency and load ?
We are interested in building a general purpose framework for benchmarking systems in order to get a better understanding of where the trade-offs are in terms of latency, throughput of the CDC system and load on the source system.
Db2 Notification System
Rather than building a polling connector for Db2 it would also be possible to create a notification system. We considered this, but decided the polling connector was simpler for a first implementation.
One way to build a notification connector for Db2 would be to:
-
Identifying change events by the usage of OS file system watchers (Linux or Windows). This can monitor the transaction log directory of the Db2 database and send events when files are modified or created.
-
Determining the exact nature of the event by reading the actual table changes with the db2ReadLog API. In principle this API can be invoked remotely as a service.
-
Determining the related Db2 data structure via SQL connection, e.g. table DDL.
The Debezium event-driven Db2 connector would wait on notifications and then read the actual changes via db2ReadLog and SQL. This would require the watcher agent to run locally on the database system, similarly to the capture server.
DML v DDL Changes
Change Data Capture (CDC) systems propagate modifications at the source tables made via Data Manipulation Language (DML) operations such as INSERT, DELETE etc. They do not explicitly handle changes to the source table made via Data Definition Language (DDL) operations such as TRUNCATE, ALTER etc. It is not really clear what the behavior of Debezium should be made when a DDL change occurs. We are looking at exploring what the Debezium model should be for changes of this sort.
Conclusion
While it is attractive to assume new enterprise data systems are built completely from scratch it will almost certainly be necessary to interact with existing relational database systems for some considerable time. Debezium is a promising framework for connecting existing enterprise data systems into data processing platforms such as Datalakes. Our work currently at IBM Research is focusing on building hybrid-cloud data-orchestration systems with Kafka and Debezium being central components.



About Debezium
Debezium is an open source distributed platform that turns your existing databases into event streams, so applications can see and respond almost instantly to each committed row-level change in the databases. Debezium is built on top of Kafka and provides Kafka Connect compatible connectors that monitor specific database management systems. Debezium records the history of data changes in Kafka logs, so your application can be stopped and restarted at any time and can easily consume all of the events it missed while it was not running, ensuring that all events are processed correctly and completely. Debezium is open source under the Apache License, Version 2.0.
Get involved
We hope you find Debezium interesting and useful, and want to give it a try. Follow us on Twitter @debezium, chat with us on Zulip, or join our mailing list to talk with the community. All of the code is open source on GitHub, so build the code locally and help us improve ours existing connectors and add even more connectors. If you find problems or have ideas how we can improve Debezium, please let us know or log an issue.