
As a follow up to the recent Building Audit Logs with Change Data Capture and Stream Processing blog post, we’d like to extend the example with admin features to make it possible to capture and fix any missing transactional data.
In the above mentioned blog post, there is a log enricher service used to combine data inserted or updated in the Vegetable database table with transaction context data such as
-
Transaction id
-
User name who performed the work
-
Use case that was behind the actual change e.g. "CREATE VEGETABLE"
This all works well as long as all the changes are done via the vegetable service. But is this always the case?
What about maintenance activities or migration scripts executed directly on the database level? There are still a lot of such activities going on, either on purpose or because that is our old habits we are trying to change…
Maintenance on database level
So let’s assume there is a need to do some maintenance on the inventory database that will essentially make changes to the data stored in the vegetable table. To make it simple, let’s just add a new entry into the vegetable table:
insert into inventory.vegetable (id, name, description) values (106, ‘cucumber, 'excellent');Once that is added you will see that the log enricher service is starting to print out quite a few log messages… and it does it constantly.
log-enricher_1 | 2019-10-11 10:30:46,099 INFO [io.deb.dem.aud.enr.ChangeEventEnricher] (auditlog-enricher-c9e5d1bb-d953-42b4-8dc6-bbc328f5344f-StreamThread-1) Processing buffered change event for key {"id":106}
log-enricher_1 | 2019-10-11 10:30:46,106 WARN [io.deb.dem.aud.enr.ChangeEventEnricher] (auditlog-enricher-c9e5d1bb-d953-42b4-8dc6-bbc328f5344f-StreamThread-1) No metadata found for transaction {"transaction_id":611}
log-enricher_1 | 2019-10-11 10:30:46,411 INFO [io.deb.dem.aud.enr.ChangeEventEnricher] (auditlog-enricher-c9e5d1bb-d953-42b4-8dc6-bbc328f5344f-StreamThread-1) Processing buffered change event for key {"id":106}
log-enricher_1 | 2019-10-11 10:30:46,415 WARN [io.deb.dem.aud.enr.ChangeEventEnricher] (auditlog-enricher-c9e5d1bb-d953-42b4-8dc6-bbc328f5344f-StreamThread-1) No metadata found for transaction {"transaction_id":611}
log-enricher_1 | 2019-10-11 10:30:46,921 INFO [io.deb.dem.aud.enr.ChangeEventEnricher] (auditlog-enricher-c9e5d1bb-d953-42b4-8dc6-bbc328f5344f-StreamThread-1) Processing buffered change event for key {"id":106}Looking at the logs you can identify that it actually refers to the entry we just inserted (id 106).
In addition to that, it refers to missing transaction context data that it cannot find. That is the
consequence of doing it manually on database level instead of going through the vegetable service.
There is no corresponding data in the dbserver1.inventory.transaction_context_data Kafka topic and thus the log enricher cannot
correlate and by that merge/enrich them.
Kogito to the rescue
There would be a really good feature (or a neat feature as Gunnar said) if we could have some sort of admin service that could help in resolving this kind of problems. Mainly because if such entry is added it will block the entire enrichment activity as the first missing message will hold off all others.
And here comes Kogito - a cloud native business automation toolkit to build intelligent business applications based on battle tested capabilities. In other words, it brings business processes and rules to solve particular business problems. In this case the business problem is blocked log enrichment which can lead to some lost opportunities (of various types).
What Kogito helps us with is to define our logic to understand what might get wrong, what needs to be done to resolve it and what are the conditions that can lead to both problem and resolution.
In this particular case we use both processes and rules to make sure we get the context right and react to the events behind the vegetable service. To be able to spot the erroneous situations we need to monitor two topics:
-
dbserver1.inventory.vegetable- vegetable data change events -
dbserver1.inventory.transaction_context_data- events from vegetable service with additional context data
So for that we define two business processes where each will be started based on incoming messages - from individual Kafka topics:
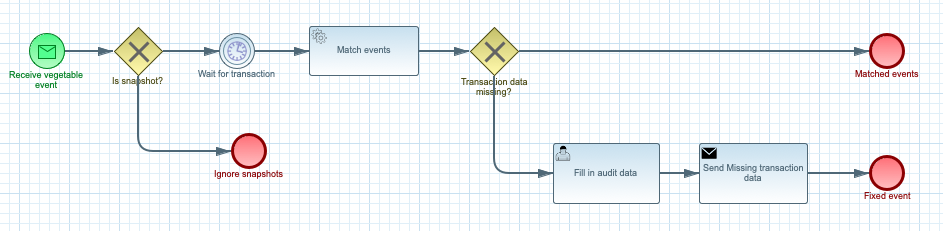

As illustrated above, both processes are initiated based on an incoming message. Then the logic afterwards is significantly different.
The "Transaction context data" process is responsible for just retrieving the event and pushing it into processing phase - that essentially means to insert it into the so called "working memory" that is used for rule evaluation. And at that moment it’s done.
The "Vegetable event" process starts in a similar way… it retrieves the message and then (first ignore snapshot messages in the same way as the log enricher service) will wait for a predefined amount of time (2 seconds) before matching vegetable and transaction context events. Once there is a match it will simple finish its execution. But if there is no match found it will create a user task (that’s a task that requires human actors to provide data before process can move forward).
This is done via admin user interface (http://localhost:8085/) that allows to easily spot such instance and work on them to fix missing data.
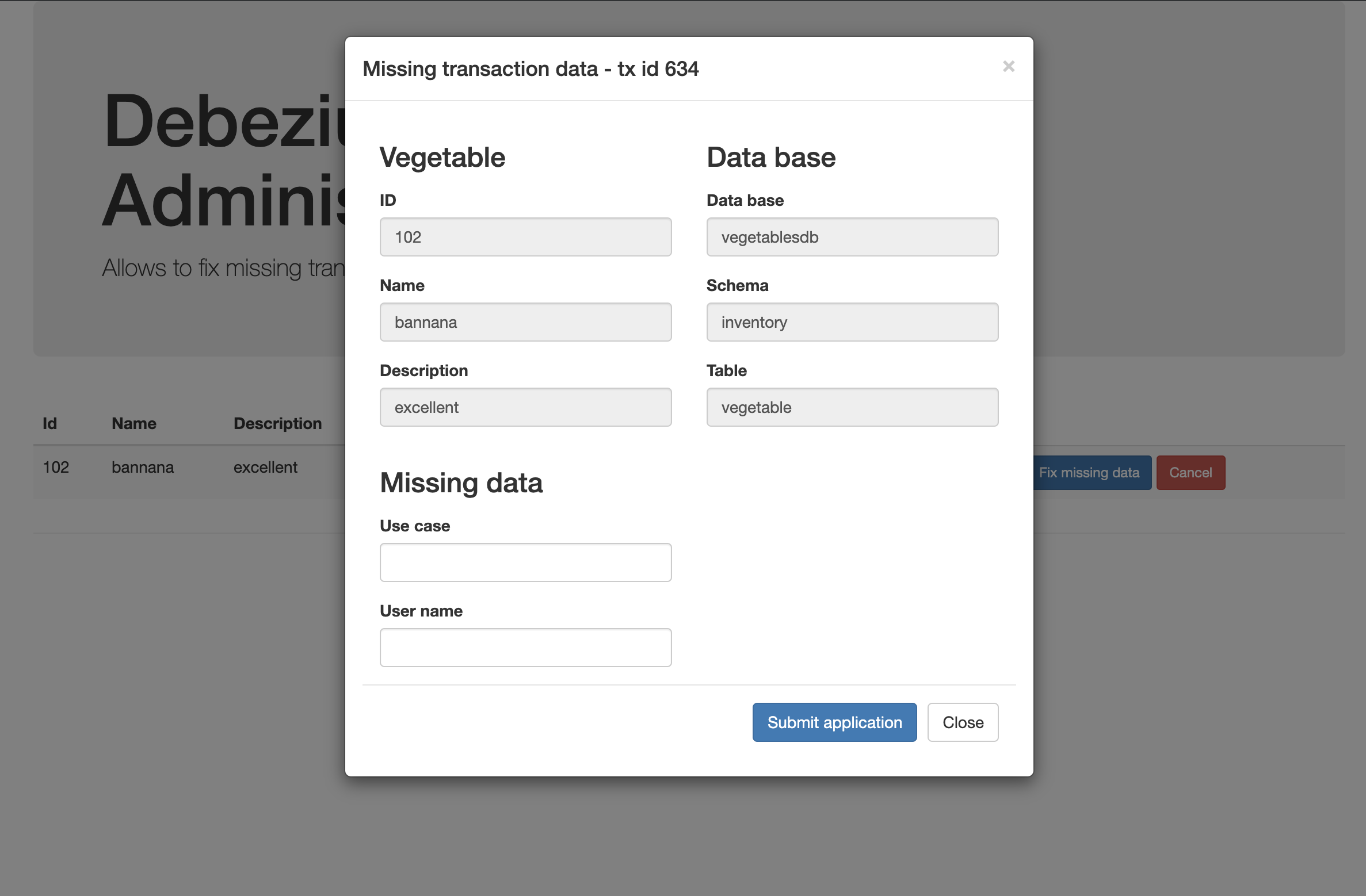
Once the Use case and User name attributes are provided, the process will create a new transaction context event,
push it to the Kafka topic and complete itself.
After the missing transaction context data event has been put on the topic the log enricher will resume its operation and you will be able to see the following lines in the log:
log-enricher_1 | 2019-10-11 10:31:00,385 INFO [io.deb.dem.aud.enr.ChangeEventEnricher] (auditlog-enricher-c9e5d1bb-d953-42b4-8dc6-bbc328f5344f-StreamThread-1) Processing buffered change event for key {"id":106}
log-enricher_1 | 2019-10-11 10:31:00,389 INFO [io.deb.dem.aud.enr.ChangeEventEnricher] (auditlog-enricher-c9e5d1bb-d953-42b4-8dc6-bbc328f5344f-StreamThread-1) Enriched change event for key {"id":106}With this you can easily administrate the audit logs to make sure any erroneous situations are resolved quickly to not affect any other activities.
And if you would like to see everything in action, just watch this video:
Or try it yourself by running the audit log example.
About Debezium
Debezium is an open source distributed platform that turns your existing databases into event streams, so applications can see and respond almost instantly to each committed row-level change in the databases. Debezium is built on top of Kafka and provides Kafka Connect compatible connectors that monitor specific database management systems. Debezium records the history of data changes in Kafka logs, so your application can be stopped and restarted at any time and can easily consume all of the events it missed while it was not running, ensuring that all events are processed correctly and completely. Debezium is open source under the Apache License, Version 2.0.
Get involved
We hope you find Debezium interesting and useful, and want to give it a try. Follow us on Twitter @debezium, chat with us on Zulip, or join our mailing list to talk with the community. All of the code is open source on GitHub, so build the code locally and help us improve ours existing connectors and add even more connectors. If you find problems or have ideas how we can improve Debezium, please let us know or log an issue.