
As part of their business logic, microservices often do not only have to update their own local data store, but they also need to notify other services about data changes that happened. The outbox pattern describes an approach for letting services execute these two tasks in a safe and consistent manner; it provides source services with instant "read your own writes" semantics, while offering reliable, eventually consistent data exchange across service boundaries.
Update (13 Sept. 2019): To simplify usage of the outbox pattern, Debezium now provides a ready-to-use SMT for routing outbox events. The custom SMT discussed in this blog post is not needed any longer.
If you’ve built a couple of microservices, you’ll probably agree that the hardest part about them is data: microservices don’t exist in isolation and very often they need to propagate data and data changes amongst each other.
For instance consider a microservice that manages purchase orders: when a new order is placed, information about that order may have to be relayed to a shipment service (so it can assemble shipments of one or more orders) and a customer service (so it can update things like the customer’s total credit balance based on the new order).
There are different approaches for letting the order service know the other two about new purchase orders; e.g. it could invoke some REST, grpc or other (synchronous) API provided by these services. This might create some undesired coupling, though: the sending service must know which other services to invoke and where to find them. It also must be prepared for these services temporarily not being available. Service meshes such as Istio can come in helpful here, by providing capabilities like request routing, retries, circuit breakers and much more.
The general issue of any synchronous approach is that one service cannot really function without the other services which it invokes. While buffering and retrying might help in cases where other services only need to be notified of certain events, this is not the case if a service actually needs to query other services for information. For instance, when a purchase order is placed, the order service might need to obtain the information how many times the purchased item is on stock from an inventory service.
Another downside of such a synchronous approach is that it lacks re-playability, i.e. the possibility for new consumers to arrive after events have been sent and still be able to consume the entire event stream from the beginning.
Both problems can be addressed by using an asynchronous data exchange approach instead: i.e having the order, inventory and other services propagate events through a durable message log such as Apache Kafka. By subscribing to these event streams, each service will be notified about the data change of other services. It can react to these events and, if needed, create a local representation of that data in its own data store, using a representation tailored towards its own needs. For instance, such view might be denormalized to efficiently support specific access patterns, or it may only contain a subset of the original data that’s relevant to the consuming service.
Durable logs also support re-playability, i.e. new consumers can be added as needed, enabling use cases you might not have had in mind originally, and without touching the source service. E.g. consider a data warehouse which should keep information about all the orders ever placed, or some full-text search functionality on purchase orders based on Elasticsearch. Once the purchase order events are in a Kafka topic (Kafka’s topic’s retention policy settings can be used to ensure that events remain in a topic as long as its needed for the given use cases and business requirements), new consumers can subscribe, process the topic from the very beginning and materialize a view of all the data in a microservice’s database, search index, data warehouse etc.
|
Dealing with Topic Growth
Depending on the amount of data (number and size of records, frequency of changes), it may or may not be feasible to keep events in topics for a long or even indefinite time. Very often, some or even all events pertaining to a given data item (e.g. a specific purchase order) might be eligible for deletion from a business point of view after a given point in time. See the box "Deletion of Events from Kafka Topics" further below for some more thoughts on the deletion of events from Kafka topics in order to keep their size within bounds. |
The Issue of Dual Writes
In order to provide their functionality, microservices will typically have their own local data store.
For instance, the order service may use a relational database to persist the information about purchase orders.
When a new order is placed, this may result in an INSERT operation in a table PurchaseOrder in the service’s database.
At the same time, the service may wish to send an event about the new order to Apache Kafka,
so to propagate that information to other interested services.
Simply issuing these two requests may lead to potential inconsistencies, though. The reason being that we cannot have one shared transaction that would span the service’s database as well as Apache Kafka, as the latter doesn’t support to be enlisted in distributed (XA) transactions. So in unfortunate circumstances it might happen that we end up with having the new purchase order persisted in the local database, but not having sent the corresponding message to Kafka (e.g. due to some networking issue). Or, the other way around, we might have sent the message to Kafka but failed to persist the purchase order in the local database. Both situations are undesirable; this may cause no shipment to be created for a seemingly successfully placed order. Or a shipment gets created, but then there’d be no trace about the corresponding purchase order in the order service itself.
So how can this situation be avoided? The answer is to only modify one of the two resources (the database or Apache Kafka) and drive the update of the second one based on that, in an eventually consistent manner. Let’s first consider the case of only writing to Apache Kafka.
When receiving a new purchase order, the order service would not do the INSERT into its database synchronously;
instead, it would only send an event describing the new order to a Kafka topic.
So only one resource gets modified at a time, and if something goes wrong with that,
we’ll find out about it instantly and report back to the caller of the order service that the request failed.
At the same time, the service itself would subscribe to that Kafka topic. That way, it will be notified when a new message arrives in the topic and it can persist the new purchase order in its database. There’s one subtle challenge here, though, and that is the lack of "read your own write" semantics. E.g. let’s assume the order service also has an API for searching for all the purchase orders of a given customer. When invoking that API right after placing a new order, due to the asynchronous nature of processing messages from the Kafka topic, it might happen that the purchase order has not yet been persisted in the service’s database and thus will not be returned by that query. That can lead to a very confusing user experience, as users for instance may miss newly placed orders in their shopping history. There are ways to deal with this situation, e.g. the service could keep newly placed purchase orders in memory and answer subsequent queries based on that. This gets quickly non-trivial though when implementing more complex queries or considering that the order service might also comprise multiple nodes in a clustered set-up, which would require propagation of that data within the cluster.
Now how would things look like when only writing to the database synchronously and driving the export of a message to Apache Kafka based on that? This is where the outbox pattern comes in.
The Outbox Pattern
The idea of this approach is to have an "outbox" table in the service’s database.
When receiving a request for placing a purchase order, not only an INSERT into the PurchaseOrder table is done,
but, as part of the same transaction,
also a record representing the event to be sent is inserted into that outbox table.
The record describes an event that happened in the service,
for instance it could be a JSON structure representing the fact that a new purchase order has been placed,
comprising data on the order itself, its order lines as well as contextual information such as a use case identifier.
By explicitly emitting events via records in the outbox table,
it can be ensured that events are structured in a way suitable for external consumers.
This also helps to make sure that event consumers won’t break
when for instance altering the internal domain model or the PurchaseOrder table.
An asynchronous process monitors that table for new entries.
If there are any, it propagates the events as messages to Apache Kafka.
This gives us a very nice balance of characteristics:
By synchronously writing to the PurchaseOrder table, the source service benefits from "read your own writes" semantics.
A subsequent query for purchase orders will return the newly persisted order, as soon as that first transaction has been committed.
At the same time, we get reliable, asynchronous, eventually consistent data propagation to other services via Apache Kafka.
Now, the outbox pattern isn’t actually a new idea. It has been in use for quite some time. In fact, even when using JMS-style message brokers, which actually could participate in distributed transactions, it can be a preferable option to avoid any coupling and potential impact by downtimes of remote resources such as a message broker. You can also find a description of the pattern on Chris Richardson’s excellent microservices.io site.
Nevertheless, the pattern gets much less attention than it deserves and it is especially useful in the context of microservices. As we’ll see, the outbox pattern can be implemented in a very elegant and efficient way using change data capture and Debezium. In the following, let’s explore how.
An Implementation Based on Change Data Capture
Log-based Change Data Capture (CDC) is a great fit for capturing new entries in the outbox table and stream them to Apache Kafka. As opposed to any polling-based approach, event capture happens with a very low overhead in near-realtime. Debezium comes with CDC connectors for several databases such as MySQL, Postgres and SQL Server. The following example will use the Debezium connector for Postgres.
You can find the complete source code of the example on GitHub. Refer to the README.md for details on building and running the example code. The example is centered around two microservices, order-service and shipment-service. Both are implemented in Java, using CDI as the component model and JPA/Hibernate for accessing their respective databases. The order service runs on WildFly and exposes a simple REST API for placing purchase orders and canceling specific order lines. It uses a Postgres database as its local data store. The shipment service is based on Thorntail; via Apache Kafka, it receives events exported by the order service and creates corresponding shipment entries in its own MySQL database. Debezium tails the transaction log ("write-ahead log", WAL) of the order service’s Postgres database in order to capture any new events in the outbox table and propagates them to Apache Kafka.
The overall architecture of the solution can be seen in the following picture:
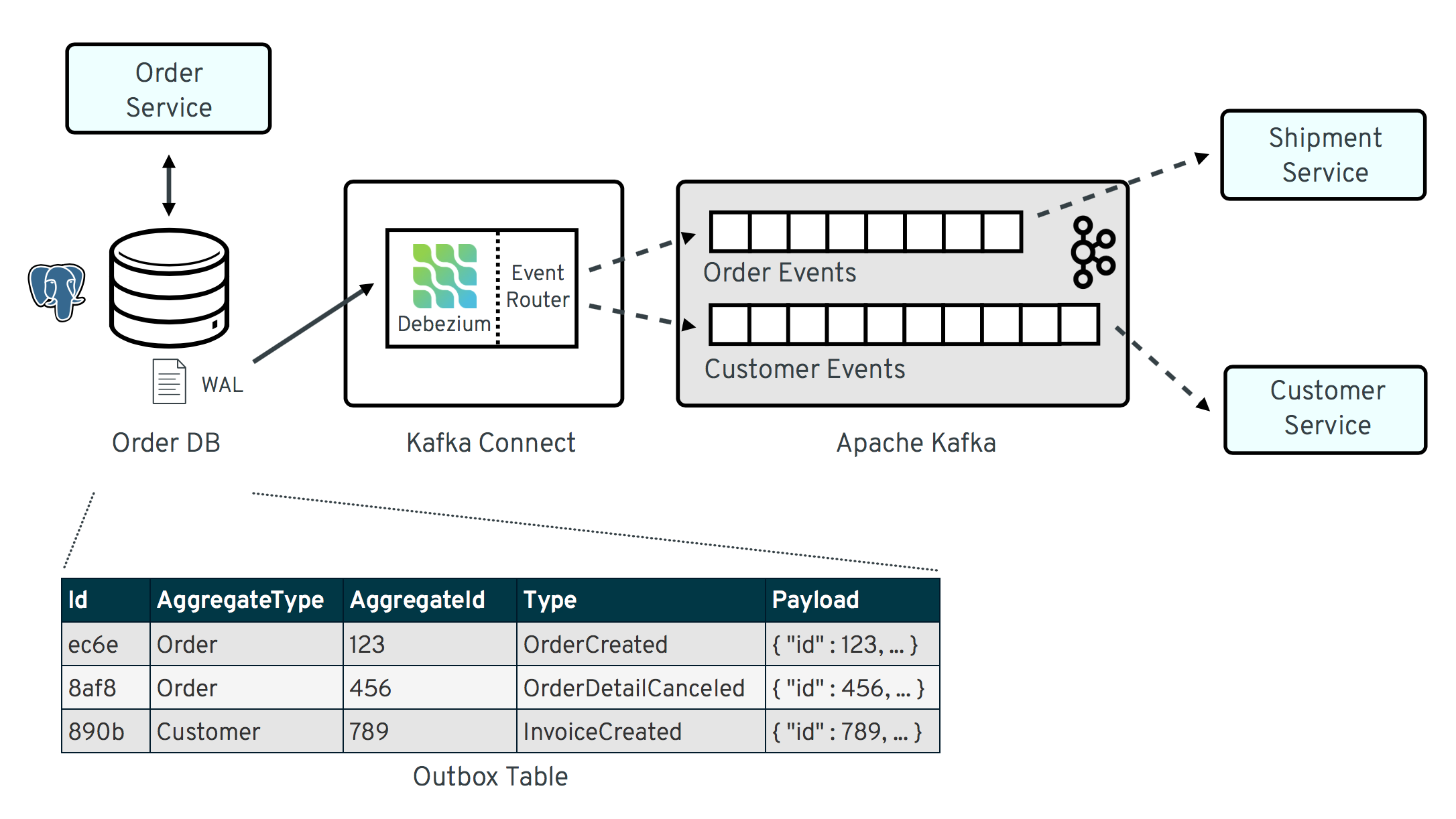
Note that the pattern is in no way tied to these specific implementation choices. It could equally well be realized using alternative technologies such as Spring Boot (e.g. leveraging Spring Data’s support for domain events), plain JDBC or other programming languages than Java altogether.
Now let’s take a closer look at some of the relevant components of the solution.
The Outbox Table
The outbox table resides in the database of the order service and has the following structure:
Column | Type | Modifiers
--------------+------------------------+-----------
id | uuid | not null
aggregatetype | character varying(255) | not null
aggregateid | character varying(255) | not null
type | character varying(255) | not null
payload | jsonb | not nullIts columns are these:
-
id: unique id of each message; can be used by consumers to detect any duplicate events, e.g. when restarting to read messages after a failure. Generated when creating a new event. -
aggregatetype: the type of the aggregate root to which a given event is related; the idea being, leaning on the same concept of domain-driven design, that exported events should refer to an aggregate ("a cluster of domain objects that can be treated as a single unit"), where the aggregate root provides the sole entry point for accessing any of the entities within the aggregate. This could for instance be "purchase order" or "customer".This value will be used to route events to corresponding topics in Kafka, so there’d be a topic for all events related to purchase orders, one topic for all customer-related events etc. Note that also events pertaining to a child entity contained within one such aggregate should use that same type. So e.g. an event representing the cancelation of an individual order line (which is part of the purchase order aggregate) should also use the type of its aggregate root, "order", ensuring that also this event will go into the "order" Kafka topic.
-
aggregateid: the id of the aggregate root that is affected by a given event; this could for instance be the id of a purchase order or a customer id; Similar to the aggregate type, events pertaining to a sub-entity contained within an aggregate should use the id of the containing aggregate root, e.g. the purchase order id for an order line cancelation event. This id will be used as the key for Kafka messages later on. That way, all events pertaining to one aggregate root or any of its contained sub-entities will go into the same partition of that Kafka topic, which ensures that consumers of that topic will consume all the events related to one and the same aggregate in the exact order as they were produced. -
type: the type of event, e.g. "Order Created" or "Order Line Canceled". Allows consumers to trigger suitable event handlers. -
payload: a JSON structure with the actual event contents, e.g. containing a purchase order, information about the purchaser, contained order lines, their price etc.
Sending Events to the Outbox
In order to "send" events to the outbox, code in the order service could in general just do an INSERT into the outbox table.
However, it’s a good idea to go for a slightly more abstract API, allowing to adjust implementation details of the outbox later on more easily, if needed.
CDI events come in very handy for this.
They can be raised in the application code and will be processed synchronously by the outbox event sender,
which will do the required INSERT into the outbox table.
All outbox event types should implement the following contract, resembling the structure of the outbox table shown before:
public interface ExportedEvent {
String getAggregateId();
String getAggregateType();
JsonNode getPayload();
String getType();
}To produce such event, application code uses an injected Event instance, as e.g. here in the OrderService class:
@ApplicationScoped
public class OrderService {
@PersistenceContext
private EntityManager entityManager;
@Inject
private Event<ExportedEvent> event;
@Transactional
public PurchaseOrder addOrder(PurchaseOrder order) {
order = entityManager.merge(order);
event.fire(OrderCreatedEvent.of(order));
event.fire(InvoiceCreatedEvent.of(order));
return order;
}
@Transactional
public PurchaseOrder updateOrderLine(long orderId, long orderLineId,
OrderLineStatus newStatus) {
// ...
}
}In the addOrder() method, the JPA entity manager is used to persist the incoming order in the database
and the injected event is used to fire a corresponding OrderCreatedEvent and an InvoiceCreatedEvent.
Again, keep in mind that, despite the notion of "event", these two things happen within one and the same transaction.
i.e. within this transaction, three records will be inserted into the database:
one in the table with purchase orders and two in the outbox table.
Actual event implementations are straight-forward;
as an example, here’s the OrderCreatedEvent class:
public class OrderCreatedEvent implements ExportedEvent {
private static ObjectMapper mapper = new ObjectMapper();
private final long id;
private final JsonNode order;
private OrderCreatedEvent(long id, JsonNode order) {
this.id = id;
this.order = order;
}
public static OrderCreatedEvent of(PurchaseOrder order) {
ObjectNode asJson = mapper.createObjectNode()
.put("id", order.getId())
.put("customerId", order.getCustomerId())
.put("orderDate", order.getOrderDate().toString());
ArrayNode items = asJson.putArray("lineItems");
for (OrderLine orderLine : order.getLineItems()) {
items.add(
mapper.createObjectNode()
.put("id", orderLine.getId())
.put("item", orderLine.getItem())
.put("quantity", orderLine.getQuantity())
.put("totalPrice", orderLine.getTotalPrice())
.put("status", orderLine.getStatus().name())
);
}
return new OrderCreatedEvent(order.getId(), asJson);
}
@Override
public String getAggregateId() {
return String.valueOf(id);
}
@Override
public String getAggregateType() {
return "Order";
}
@Override
public String getType() {
return "OrderCreated";
}
@Override
public JsonNode getPayload() {
return order;
}
}Note how Jackson’s ObjectMapper is used to create a JSON representation of the event’s payload.
Now let’s take a look at the code that consumes any fired ExportedEvent and does the corresponding write to the outbox table:
@ApplicationScoped
public class EventSender {
@PersistenceContext
private EntityManager entityManager;
public void onExportedEvent(@Observes ExportedEvent event) {
OutboxEvent outboxEvent = new OutboxEvent(
event.getAggregateType(),
event.getAggregateId(),
event.getType(),
event.getPayload()
);
entityManager.persist(outboxEvent);
entityManager.remove(outboxEvent);
}
}It’s rather simple: for each event the CDI runtime will invoke the onExportedEvent() method.
An instance of the OutboxEvent entity is persisted in the database — and removed right away!
This might be surprising at first.
But it makes sense when remembering how log-based CDC works:
it doesn’t examine the actual contents of the table in the database, but instead it tails the append-only transaction log.
The calls to persist() and remove() will create an INSERT and a DELETE entry in the log once the transaction commits.
After that, Debezium will process these events:
for any INSERT, a message with the event’s payload will be sent to Apache Kafka.
DELETE events on the other hand can be ignored,
as the removal from the outbox table is a mere technicality that doesn’t require any propagation to the message broker.
So we are able to capture the event added to the outbox table by means of CDC,
but when looking at the contents of the table itself, it will always be empty.
This means that no additional disk space is needed for the table
(apart from the log file elements which will automatically be discarded at some point)
and also no separate house-keeping process is required to stop it from growing indefinitely.
Registering the Debezium Connector
With the outbox implementation in place, it’s time to register the Debezium Postgres connector, so it can capture any new events in the outbox table and relay them to Apache Kafka. That can be done by POST-ing the following JSON request to the REST API of Kafka Connect:
{
"name": "outbox-connector",
"config": {
"connector.class" : "io.debezium.connector.postgresql.PostgresConnector",
"tasks.max" : "1",
"database.hostname" : "order-db",
"database.port" : "5432",
"database.user" : "postgresuser",
"database.password" : "postgrespw",
"database.dbname" : "orderdb",
"database.server.name" : "dbserver1",
"schema.whitelist" : "inventory",
"table.whitelist" : "inventory.outboxevent",
"tombstones.on.delete" : "false",
"transforms" : "router",
"transforms.router.type" : "io.debezium.examples.outbox.routingsmt.EventRouter"
}
}This sets up an instance of io.debezium.connector.postgresql.PostgresConnector,
capturing changes from the specified Postgres instance.
Note that by means of a table whitelist, only changes from the outboxevent table are captured.
It also applies a single message transform (SMT) named EventRouter.
|
Deletion of Events from Kafka Topics
By setting the Alternatively, one could work with compacted topics. This would require some changes to the design of events in the outbox table:
Naturally, when deleting events, the event stream will not be re-playable from its very beginning any longer.
Depending on the specific business requirements, it might be sufficient to just keep the final state of a given purchase order, customer etc.
This could be achieved using compacted topics and a sufficiently value for the topic’s |
Topic Routing
By default, the Debezium connectors will send all change events originating from one given table to the same topic,
i.e. we’d end up with a single Kafka topic named dbserver1.inventory.outboxevent which would contain all events,
be it order events, customer events etc.
To simplify the implementation of consumers which are only interested in specific event types it makes more sense, though,
to have multiple topics, e.g. OrderEvents, CustomerEvents and so on.
For instance the shipment service might not be interested in any customer events.
By only subscribing to the OrderEvents topic, it will be sure to never receive any customer events.
In order to route the change events captured from the outbox table to different topics, that custom SMT EventRouter is used.
Here is the code of its apply() method, which will be invoked by Kafka Connect for each record emitted by the Debezium connector:
@Override
public R apply(R record) {
// Ignoring tombstones just in case
if (record.value() == null) {
return record;
}
Struct struct = (Struct) record.value();
String op = struct.getString("op");
// ignoring deletions in the outbox table
if (op.equals("d")) {
return null;
}
else if (op.equals("c")) {
Long timestamp = struct.getInt64("ts_ms");
Struct after = struct.getStruct("after");
String key = after.getString("aggregateid");
String topic = after.getString("aggregatetype") + "Events";
String eventId = after.getString("id");
String eventType = after.getString("type");
String payload = after.getString("payload");
Schema valueSchema = SchemaBuilder.struct()
.field("eventType", after.schema().field("type").schema())
.field("ts_ms", struct.schema().field("ts_ms").schema())
.field("payload", after.schema().field("payload").schema())
.build();
Struct value = new Struct(valueSchema)
.put("eventType", eventType)
.put("ts_ms", timestamp)
.put("payload", payload);
Headers headers = record.headers();
headers.addString("eventId", eventId);
return record.newRecord(topic, null, Schema.STRING_SCHEMA, key, valueSchema, value,
record.timestamp(), headers);
}
// not expecting update events, as the outbox table is "append only",
// i.e. event records will never be updated
else {
throw new IllegalArgumentException("Record of unexpected op type: " + record);
}
}When receiving a delete event (op = d), it will discard that event,
as that deletion of event records from the outbox table is not relevant to downstream consumers.
Things get more interesting, when receiving a create event (op = c).
Such record will be propagated to Apache Kafka.
Debezium’s change events have a complex structure, that contain the old (before) and new (after) state of the represented row.
The event structure to propagate is obtained from the after state.
The aggregatetype value from the captured event record is used to build the name of the topic to send the event to.
For instance, events with aggregatetype set to Order will be sent to the OrderEvents topic.
aggregateid is used as the message key, making sure all messages of that aggregate will go into the same partition of that topic.
The message value is a structure comprising the original event payload (encoded as JSON),
the timestamp indicating when the event was produced and the event type.
Finally, the event UUID is propagated as a Kafka header field.
This allows for efficient duplicate detection by consumers, without having to examine the actual message contents.
Events in Apache Kafka
Now let’s take a look into the OrderEvents and CustomerEvents topics.
If you have checked out the example sources and started all the components via Docker Compose (see the README.md file in the example project for more details), you can place purchase orders via the order service’s REST API like so:
cat resources/data/create-order-request.json | http POST http://localhost:8080/order-service/rest/ordersSimilarly, specific order lines can be canceled:
cat resources/data/cancel-order-line-request.json | http PUT http://localhost:8080/order-service/rest/orders/1/lines/2When using a tool such as the very practical kafkacat utility,
you should now see messages like these in the OrderEvents topic:
kafkacat -b kafka:9092 -C -o beginning -f 'Headers: %h\nKey: %k\nValue: %s\n' -q -t OrderEventsHeaders: eventId=d03dfb18-8af8-464d-890b-09eb8b2dbbdd
Key: "4"
Value: {"eventType":"OrderCreated","ts_ms":1550307598558,"payload":"{\"id\": 4, \"lineItems\": [{\"id\": 7, \"item\": \"Debezium in Action\", \"status\": \"ENTERED\", \"quantity\": 2, \"totalPrice\": 39.98}, {\"id\": 8, \"item\": \"Debezium for Dummies\", \"status\": \"ENTERED\", \"quantity\": 1, \"totalPrice\": 29.99}], \"orderDate\": \"2019-01-31T12:13:01\", \"customerId\": 123}"}
Headers: eventId=49f89ea0-b344-421f-b66f-c635d212f72c
Key: "4"
Value: {"eventType":"OrderLineUpdated","ts_ms":1550308226963,"payload":"{\"orderId\": 4, \"newStatus\": \"CANCELLED\", \"oldStatus\": \"ENTERED\", \"orderLineId\": 7}"}The payload field with the message values is the string-ified JSON representation of the original events.
The Debezium Postgres connector emits JSONB columns as a string
(using the io.debezium.data.Json logical type name),
which is why the quotes are escaped.
The jq utility, and more specifically,
its fromjson operator, come in handy for displaying the event payload in a more readable way:
kafkacat -b kafka:9092 -C -o beginning -t Order | jq '.payload | fromjson'{
"id": 4,
"lineItems": [
{
"id": 7,
"item": "Debezium in Action",
"status": "ENTERED",
"quantity": 2,
"totalPrice": 39.98
},
{
"id": 8,
"item": "Debezium for Dummies",
"status": "ENTERED",
"quantity": 1,
"totalPrice": 29.99
}
],
"orderDate": "2019-01-31T12:13:01",
"customerId": 123
}
{
"orderId": 4,
"newStatus": "CANCELLED",
"oldStatus": "ENTERED",
"orderLineId": 7
}You can also take a look at the CustomerEvents topic to inspect the events representing the creation of an invoice when a purchase order is added.
Duplicate Detection in the Consuming Service
At this point, our implementation of the outbox pattern is fully functional;
when the order service receives a request to place an order
(or cancel an order line),
it will persist the corresponding state in the purchaseorder and orderline tables of its database.
At the same time, within the same transaction, corresponding event entries will be added to the outbox table in the same database.
The Debezium Postgres connector captures any insertions into that table
and routes the events into the Kafka topic corresponding to the aggregate type represented by a given event.
To wrap things up, let’s explore how another microservice such as the shipment service can consume these messages.
The entry point into that service is a regular Kafka consumer implementation,
which is not too exciting and hence omitted here for the sake of brevity.
You can find its source code in the example repository.
For each incoming message on the Order topic, the consumer calls the OrderEventHandler:
@ApplicationScoped
public class OrderEventHandler {
private static final Logger LOGGER = LoggerFactory.getLogger(OrderEventHandler.class);
@Inject
private MessageLog log;
@Inject
private ShipmentService shipmentService;
@Transactional
public void onOrderEvent(UUID eventId, String key, String event) {
if (log.alreadyProcessed(eventId)) {
LOGGER.info("Event with UUID {} was already retrieved, ignoring it", eventId);
return;
}
JsonObject json = Json.createReader(new StringReader(event)).readObject();
JsonObject payload = json.containsKey("schema") ? json.getJsonObject("payload") :json;
String eventType = payload.getString("eventType");
Long ts = payload.getJsonNumber("ts_ms").longValue();
String eventPayload = payload.getString("payload");
JsonReader payloadReader = Json.createReader(new StringReader(eventPayload));
JsonObject payloadObject = payloadReader.readObject();
if (eventType.equals("OrderCreated")) {
shipmentService.orderCreated(payloadObject);
}
else if (eventType.equals("OrderLineUpdated")) {
shipmentService.orderLineUpdated(payloadObject);
}
else {
LOGGER.warn("Unkown event type");
}
log.processed(eventId);
}
}The first thing done by onOrderEvent() is to check whether the event with the given UUID has been processed before.
If so, any further calls for that same event will be ignored.
This is to prevent any duplicate processing of events caused by the "at least once" semantics of this data pipeline.
For instance it could happen that the Debezium connector or the consuming service fail
before acknowledging the retrieval of a specific event with the source database or the messaging broker, respectively.
In that case, after a restart of Debezium or the consuming service,
a few events may be processed a second time.
Propagating the event UUID as a Kafka message header allows for an efficient detection and exclusion of duplicates in the consumer.
If a message is received for the first time, the message value is parsed and the business method of the ShippingService method corresponding to the specific event type is invoked with the event payload.
Finally, the message is marked as processed with the message log.
This MessageLog simply keeps track of all consumed events in a table within the service’s local database:
@ApplicationScoped
public class MessageLog {
@PersistenceContext
private EntityManager entityManager;
@Transactional(value=TxType.MANDATORY)
public void processed(UUID eventId) {
entityManager.persist(new ConsumedMessage(eventId, Instant.now()));
}
@Transactional(value=TxType.MANDATORY)
public boolean alreadyProcessed(UUID eventId) {
return entityManager.find(ConsumedMessage.class, eventId) != null;
}
}That way, should the transaction be rolled back for some reason, also the original message will not be marked as processed and an exception would bubble up to the Kafka event consumer loop. This allows for re-trying to process the message later on.
Note that a more complete implementation should take care of re-trying given messages only for a certain number of times, before re-routing any unprocessable messages to a dead-letter queue or similar. Also there should be some house-keeping on the message log table; periodically, all events older than the consumer’s current offset committed with the broker may be deleted, as it’s ensured that such messages won’t be propagated to the consumer another time.
Summary
The outbox pattern is a great way for propagating data amongst different microservices.
By only modifying a single resource - the source service’s own database - it avoids any potential inconsistencies of altering multiple resources at the same time which don’t share one common transactional context (the database and Apache Kafka). By writing to the database first, the source service has instant "read your own writes" semantics, which is important for a consistent user experience, allowing query methods invoked following to a write to instantly reflect any data changes.
At the same time, the pattern enables asynchronous event propagation to other microservices. Apache Kafka acts as a highly scalable and reliable backbone for the messaging amongst the services. Given the right topic retention settings, new consumers may come up long after an event has been originally produced, and build up their own local state based on the event history.
Putting Apache Kafka into the center of the overall architecture also ensures a decoupling of involved services. If for instance single components of the solution fail or are not available for some time, e.g. during an update, events will simply be processed later on: after a restart, the Debezium connector will continue to tail the outbox table from the point where it left off before. Similarly, any consumer will continue to process topics from its previous offset. By keeping track of already successfully processed messages, duplicates can be detected and excluded from repeated handling.
Naturally, such event pipeline between different services is eventually consistent, i.e. consumers such as the shipping service may lag a bit behind producers such as the order service. Usually, that’s just fine, though, and can be handled in terms of the application’s business logic. For instance there’ll typically be no need to create a shipment within the very same second as an order has been placed. Also, end-to-end delays of the overall solution are typically low (seconds or even sub-second range), thanks to log-based change data capture which allows for emission of events in near-realtime.
One last thing to keep in mind is that the structure of the events exposed via the outbox should be considered a part of the emitting service’s API. I.e. when needed, their structure should be adjusted carefully and with compatibility considerations in mind. This is to ensure to not accidentally break any consumers when upgrading the producing service. At the same time, consumers should be lenient when handling messages and for instance not fail when encountering unknown attributes within received events.
Many thanks to Hans-Peter Grahsl, Jiri Pechanec, Justin Holmes and René Kerner for their feedback while writing this post!
About Debezium
Debezium is an open source distributed platform that turns your existing databases into event streams, so applications can see and respond almost instantly to each committed row-level change in the databases. Debezium is built on top of Kafka and provides Kafka Connect compatible connectors that monitor specific database management systems. Debezium records the history of data changes in Kafka logs, so your application can be stopped and restarted at any time and can easily consume all of the events it missed while it was not running, ensuring that all events are processed correctly and completely. Debezium is open source under the Apache License, Version 2.0.
Get involved
We hope you find Debezium interesting and useful, and want to give it a try. Follow us on Twitter @debezium, chat with us on Zulip, or join our mailing list to talk with the community. All of the code is open source on GitHub, so build the code locally and help us improve ours existing connectors and add even more connectors. If you find problems or have ideas how we can improve Debezium, please let us know or log an issue.