
The second-level cache of Hibernate ORM / JPA is a proven and efficient way to increase application performance: caching read-only or rarely modified entities avoids roundtrips to the database, resulting in improved response times of the application.
Unlike the first-level cache, the second-level cache is associated with the session factory (or entity manager factory in JPA terms), so its contents are shared across transactions and concurrent sessions. Naturally, if a cached entity gets modified, the corresponding cache entry must be updated (or purged from the cache), too. As long as the data changes are done through Hibernate ORM, this is nothing to worry about: the ORM will update the cache automatically.
Things get tricky, though, when bypassing the application, e.g. when modifying records directly in the database. Hibernate ORM then has no way of knowing that the cached data has become stale, and it’s necessary to invalidate the affected items explicitly. A common way for doing so is to foresee some admin functionality that allows to clear an application’s caches. For this to work, it’s vital to not forget about calling that invalidation functionality, or the application will keep working with outdated cached data.
In the following we’re going to explore an alternative approach for cache invalidation, which works in a reliable and fully automated way: by employing Debezium and its change data capture (CDC) capabilities, you can track data changes in the database itself and react to any applied change. This allows to invalidate affected cache entries in near-realtime, without the risk of stale data due to missed changes. If an entry has been evicted from the cache, Hibernate ORM will load the latest version of the entity from the database the next time is requested.
The Example Application
As an example, consider this simple model of two entities, PurchaseOrder and Item:

A purchase order represents the order of an item, where its total price is the ordered quantity times the item’s base price.
|
Source Code
The source code of this example is provided on GitHub. If you want to follow along and try out all the steps described in the following, clone the repo and follow the instructions in README.md for building the project. |
Modelling order and item as JPA entities is straight-forward:
@Entity
public class PurchaseOrder {
@Id
@GeneratedValue(generator = "sequence")
@SequenceGenerator(
name = "sequence", sequenceName = "seq_po", initialValue = 1001, allocationSize = 50
)
private long id;
private String customer;
@ManyToOne private Item item;
private int quantity;
private BigDecimal totalPrice;
// ...
}As changes to items are rare, the Item entity should be cached.
This can be done by simply specifying JPA’s @Cacheable annotation:
@Entity
@Cacheable
public class Item {
@Id
private long id;
private String description;
private BigDecimal price;
// ...
}You also need to enable the second-level cache in the META-INF/persistence.xml file.
The property hibernate.cache.use_second_level_cache activates the cache itself, and the ENABLE_SELECTIVE cache mode
causes only those entities to be put into the cache which are annotated with @Cacheable.
It’s also a good idea to enable SQL query logging and cache access statistics.
That way you’ll be able to verify whether things work as expected by examining the application log:
<?xml version="1.0" encoding="utf-8"?>
<persistence xmlns="http://xmlns.jcp.org/xml/ns/persistence"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="..."
version="2.2">
<persistence-unit name="orders-PU-JTA" transaction-type="JTA">
<jta-data-source>java:jboss/datasources/OrderDS</jta-data-source>
<shared-cache-mode>ENABLE_SELECTIVE</shared-cache-mode>
<properties>
<property name="hibernate.cache.use_second_level_cache" value="true" />
<property name="hibernate.show_sql" value="true" />
<property name="hibernate.format_sql" value="true" />
<property name="hibernate.generate_statistics" value="true" />
<!-- dialect etc. ... -->
</properties>
</persistence-unit>
</persistence>When running on a Java EE application server (or Jakarta EE how the stack is called after it has been donated to the Eclipse Foundation), that’s all you need to enable second-level caching. In the case of WildFly (which is what’s used in the example project), the Infinispan key/value store is used as the cache provider by default.
Now try and see what happens when modifying an item’s price by running some SQL in the database,
bypassing the application layer.
If you’ve checked out the example source code, comment out the DatabaseChangeEventListener class and start the application as described in the README.md.
You then can place purchase orders using curl like this
(a couple of example items have been persisted at application start-up):
> curl -H "Content-Type: application/json" \
-X POST \
--data '{ "customer" : "Billy-Bob", "itemId" : 10003, "quantity" : 2 }' \
http://localhost:8080/cache-invalidation/rest/orders{
"id" : 1002,
"customer" : "Billy-Bob",
"item" : {
"id" :10003,
"description" : "North By Northwest",
"price" : 14.99
},
"quantity" : 2,
"totalPrice" : 29.98
}The response is the expected one, as the item price is 14.99. Now update the item’s price directly in the database. The example uses Postgres, so you can use the psql CLI utility to do so:
docker-compose exec postgres bash -c 'psql -U $POSTGRES_USER $POSTGRES_DB -c "UPDATE item SET price = 20.99 where id = 10003"'Placing another purchase order for the same item using curl, you’ll see that the calculated total price doesn’t reflect the update. Not good! But it’s not too surprising, given that the price update was applied completely bypassing the application layer and Hibernate ORM.
The Change Event Handler
Now let’s explore how to use Debezium and CDC to react to changes in the item table and invalidate corresponding cache entries.
While Debezium most of the times is deployed into Kafka Connect (thus streaming change events into Apache Kafka topics), it has another mode of operation that comes in very handy for the use case at hand. Using the embedded engine, you can run the Debezium connectors as a library directly within your application. For each change event received from the database, a configured callback method will be invoked, which in the case at hand will evict the affected item from the second-level cache.
The following picture shows the design of this approach:
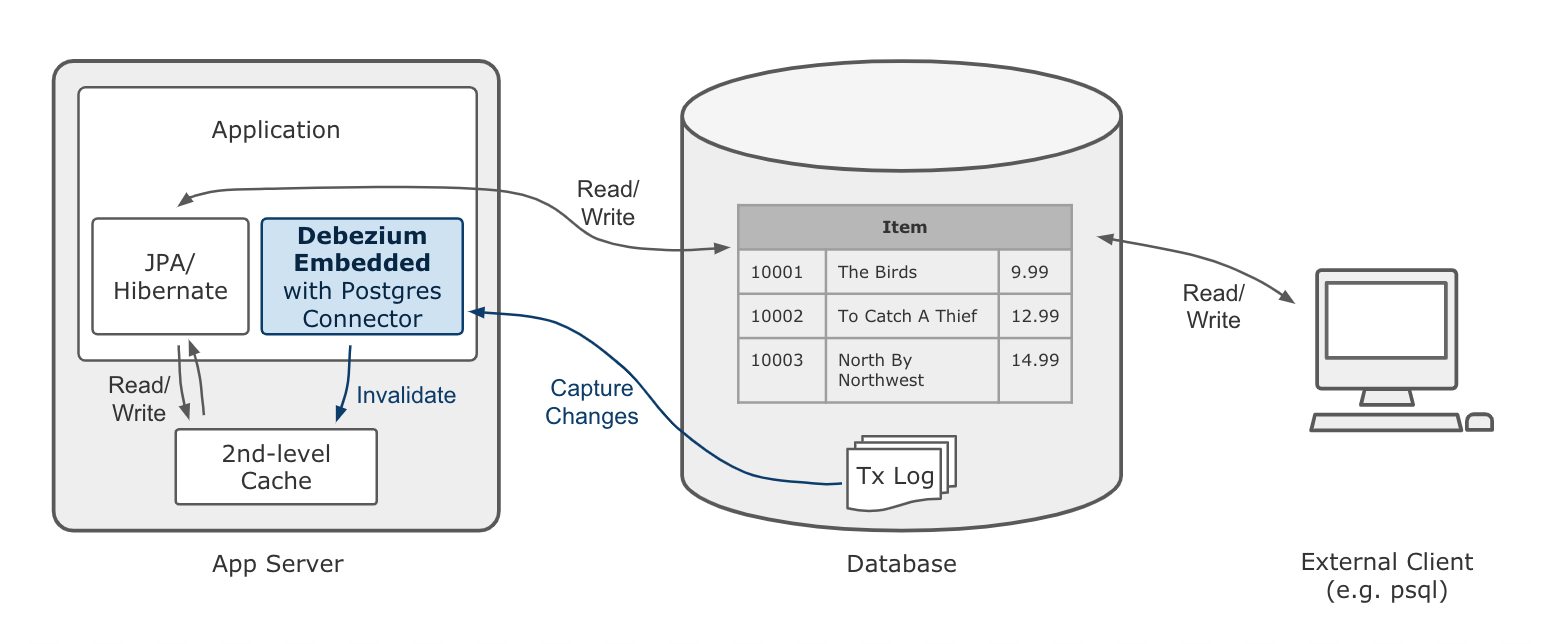
While this doesn’t come with the scalability and fault tolerance provided by Apache Kafka, it nicely fits the given requirements. As the second-level cache is bound to the application lifecycle, there is for instance no need for the offset management and restarting capabilities provided by the Kafka Connect framework. For the given use case it is enough to receive data change events while the application is running, and using the embedded engine enables exactly that.
|
Clustered Applications
Note that it still might make sense to use Apache Kafka and the regular deployment of Debezium into Kafka Connect when running a clustered application where each node has a local cache. Instead of registering a connector on each node, Kafka and Connect would allow you to deploy a single connector instance and have the application nodes listen to the topic(s) with the change events. This would result in less resource utilization in the database. |
Having added the dependencies of the Debezium embedded engine (io.debezium:debezium-embedded:0.9.0.Beta1) and the Debezium Postgres connector (io.debezium:debezium-connector-postgres:0.9.0.Beta1) to your project,
a class DatabaseChangeEventListener for listening to any changes in the database can be implemented like this:
@ApplicationScoped
public class DatabaseChangeEventListener {
@Resource
private ManagedExecutorService executorService;
@PersistenceUnit private EntityManagerFactory emf;
@PersistenceContext
private EntityManager em;
private EmbeddedEngine engine;
public void startEmbeddedEngine(@Observes @Initialized(ApplicationScoped.class) Object init) {
Configuration config = Configuration.empty()
.withSystemProperties(Function.identity()).edit()
.with(EmbeddedEngine.CONNECTOR_CLASS, PostgresConnector.class)
.with(EmbeddedEngine.ENGINE_NAME, "cache-invalidation-engine")
.with(EmbeddedEngine.OFFSET_STORAGE, MemoryOffsetBackingStore.class)
.with("name", "cache-invalidation-connector")
.with("database.hostname", "postgres")
.with("database.port", 5432)
.with("database.user", "postgresuser")
.with("database.password", "postgrespw")
.with("database.server.name", "dbserver1")
.with("database.dbname", "inventory")
.with("database.whitelist", "public")
.with("snapshot.mode", "never")
.build();
this.engine = EmbeddedEngine.create()
.using(config)
.notifying(this::handleDbChangeEvent)
.build();
executorService.execute(engine);
}
@PreDestroy
public void shutdownEngine() {
engine.stop();
}
private void handleDbChangeEvent(SourceRecord record) {
if (record.topic().equals("dbserver1.public.item")) {
Long itemId = ((Struct) record.key()).getInt64("id");
Struct payload = (Struct) record.value();
Operation op = Operation.forCode(payload.getString("op"));
if (op == Operation.UPDATE || op == Operation.DELETE) {
emf.getCache().evict(Item.class, itemId);
}
}
}
}Upon application start-up, this configures an instance of the Debezium Postgres connector and sets up the embedded engine for running the connector. The connector options (host name, credentials etc.) are mostly the same as when deploying the connector into Kafka Connect. There is no need for doing an initial snapshot of the existing data, hence the snapshot mode is set to "never".
The offset storage option is used for controlling how connector offsets should be persisted. As it’s not necessary to process any change events occurring while the connector is not running (instead you’d just begin to read the log from the current location after the restart), the in-memory implementation provided by Kafka Connect is used.
Once configured, the embedded engine must be run via an Executor instance.
As the example runs in WildFly, a managed executor can simply be obtained through @Resource injection for that purpose (see JSR 236).
The embedded engine is configured to invoke the handleDbChangeEvent() method for each received data change event.
In this method it first is checked whether the incoming event originates from the item table.
If that’s the case, and if the change event represents an UPDATE or DELETE statement,
the affected Item instance is evicted from the second-level cache.
JPA 2.0 provides a simple API for this purpose which is accessible via the EntityManagerFactory.
With the DatabaseChangeEventListener class in place, the cache entry will now automatically be evicted when doing another item update via psql.
When placing the first purchase order for that item after the update, you’ll see in the application log how Hibernate ORM executes a query SELECT ... FROM item ... in order to load the item referenced by the order.
Also the cache statistics will report one "L2C miss".
Upon subsequent orders of that same item it will be obtained from the cache again.
|
Eventual Consistency
While the event handling happens in near-realtime, it’s important to point out that it still applies eventual consistency semantics. This means that there is a very short time window between the point in time where a transaction is committed and the point in time where the change event is streamed from the log to the event handler and the cache entry is invalidated. |
Avoiding Cache Invalidations After Application-triggered Data Changes
The change event listener shown above satisfies the requirement of invalidating cached items after external data changes.
But in its current form it is evicting cache items a bit too aggressively:
cached items will also be purged when updating an Item instance through the application itself.
This is not only not needed (as the cached item already is the current version), but it’s even counter-productive:
the superfluous cache evictions will cause additional database roundtrips, resulting in longer response times.
It is therefore necessary to distinguish between data changes performed by the application itself and external data changes. Only in the latter case the affected items should be evicted from the cache. In order to do so, you can leverage the fact that each Debezium data change event contains the id of the originating transaction. Keeping track of all transactions run by the application itself allows to trigger the cache eviction only for those items altered by external transactions.
Accounting for this change, the overall architecture looks like so:
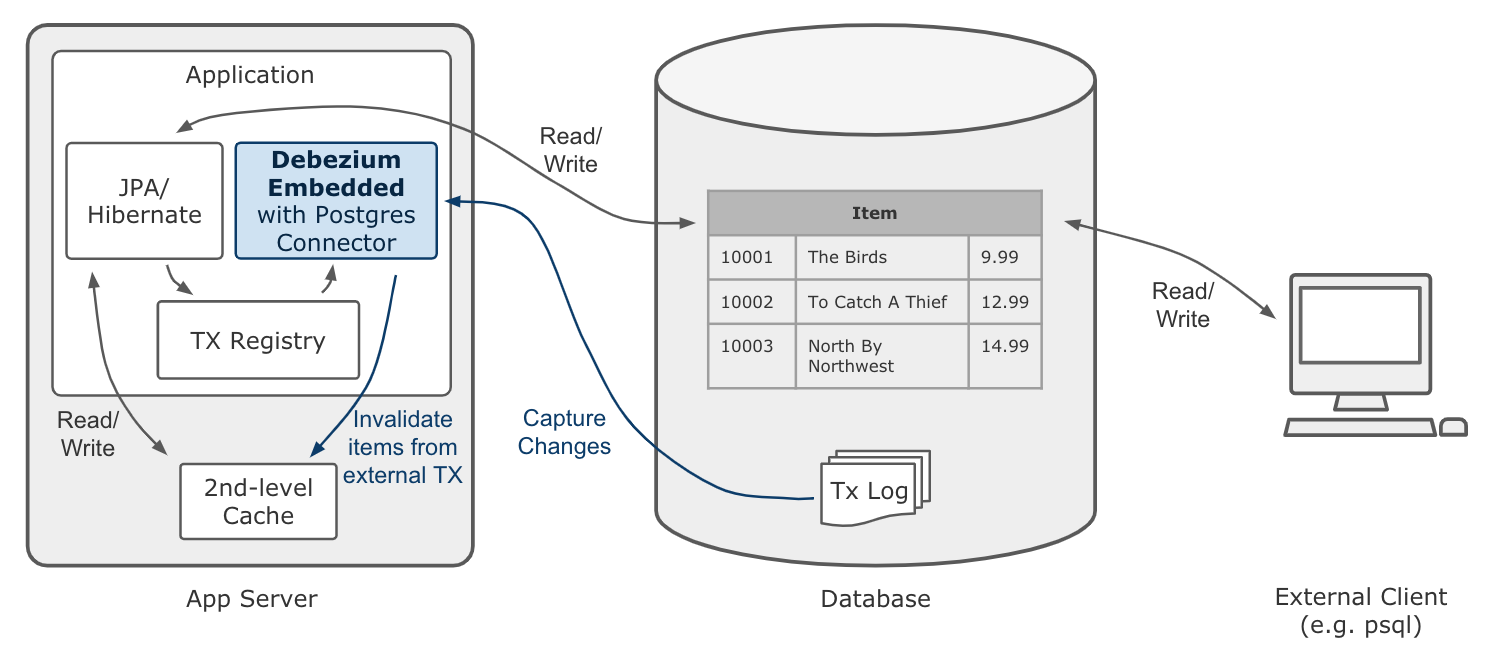
The first thing to implement is the transaction registry, i.e. a class for the transaction book keeping:
@ApplicationScoped
public class KnownTransactions {
private final DefaultCacheManager cacheManager;
private final Cache<Long, Boolean> applicationTransactions;
public KnownTransactions() {
cacheManager = new DefaultCacheManager();
cacheManager.defineConfiguration(
"tx-id-cache",
new ConfigurationBuilder()
.expiration()
.lifespan(60, TimeUnit.SECONDS)
.build()
);
applicationTransactions = cacheManager.getCache("tx-id-cache");
}
@PreDestroy
public void stopCacheManager() {
cacheManager.stop();
}
public void register(long txId) {
applicationTransactions.put(txId, true);
}
public boolean isKnown(long txId) {
return Boolean.TRUE.equals(applicationTransactions.get(txId));
}
}This uses the Infinispan DefaultCacheManager for creating and maintaining an in-memory cache of transaction ids encountered by the application.
As data change events arrive in near-realtime, the TTL of the cache entries can be rather short
(in fact, the value of one minute shown in the example is chosen very conservatively, usually events should be received within seconds).
The next step is to retrieve the current transaction id whenever a request is processed by the application and register it within KnownTransactions.
This should happen once per transaction.
There are multiple ways for implementing this logic; in the following a Hibernate ORM FlushEventListener is used for this purpose:
class TransactionRegistrationListener implements FlushEventListener {
private volatile KnownTransactions knownTransactions;
public TransactionRegistrationListener() {
}
@Override
public void onFlush(FlushEvent event) throws HibernateException {
event.getSession().getActionQueue().registerProcess( session -> {
Number txId = (Number) event.getSession().createNativeQuery("SELECT txid_current()")
.setFlushMode(FlushMode.MANUAL)
.getSingleResult();
getKnownTransactions().register(txId.longValue());
} );
}
private KnownTransactions getKnownTransactions() {
KnownTransactions value = knownTransactions;
if (value == null) {
knownTransactions = value = CDI.current().select(KnownTransactions.class).get();
}
return value;
}
}As there’s no portable way to obtain the transaction id, this is done using a native SQL query.
In the case of Postgres, the txid_current() function can be called for that.
Hibernate ORM event listeners are not subject to dependency injection via CDI.
Hence the static current() method is used to obtain a handle to the application’s CDI container and get a reference to the KnownTransactions bean.
This listener will be invoked whenever Hibernate ORM is synchronizing its persistence context with the database ("flushing"), which usually happens exactly once when the transaction is committed.
|
Manual Flushes
The session / entity manager can also be flushed manually, in which case the |
To register the flush listener with Hibernate ORM, an Integrator implementation must be created and declared in the META-INF/services/org.hibernate.integrator.spi.Integrator file:
public class TransactionRegistrationIntegrator implements Integrator {
@Override
public void integrate(Metadata metadata, SessionFactoryImplementor sessionFactory,
SessionFactoryServiceRegistry serviceRegistry) {
serviceRegistry.getService(EventListenerRegistry.class)
.appendListeners(EventType.FLUSH, new TransactionRegistrationListener());
}
@Override
public void disintegrate(SessionFactoryImplementor sessionFactory,
SessionFactoryServiceRegistry serviceRegistry) {
}
}io.debezium.examples.cacheinvalidation.persistence.TransactionRegistrationIntegratorDuring bootstrap, Hibernate ORM will detect the integrator class (by means of the Java service loader),
invoke its integrate() method which in turn will register the listener class for the FLUSH event.
The last step is to exclude any events stemming from transactions run by the application itself in the database change event handler:
@ApplicationScoped
public class DatabaseChangeEventListener {
// ...
@Inject
private KnownTransactions knownTransactions;
private void handleDbChangeEvent(SourceRecord record) {
if (record.topic().equals("dbserver1.public.item")) {
Long itemId = ((Struct) record.key()).getInt64("id");
Struct payload = (Struct) record.value();
Operation op = Operation.forCode(payload.getString("op"));
Long txId = ((Struct) payload.get("source")).getInt64("txId");
if (!knownTransactions.isKnown(txId) &&
(op == Operation.UPDATE || op == Operation.DELETE)) {
emf.getCache().evict(Item.class, itemId);
}
}
}
}And with that, you got all the pieces in place: cached Items will only be evicted after external data changes, but not after changes done by the application itself.
To confirm, you can invoke the example’s items resource using curl:
> curl -H "Content-Type: application/json" \
-X PUT \
--data '{ "description" : "North by Northwest", "price" : 20.99}' \
http://localhost:8080/cache-invalidation/rest/items/10003When placing the next order for the item after this update, you should see that the Item entity is obtained from the cache,
i.e. the change event will not have caused the item’s cache entry to be evicted.
In contrast, if you update the item’s price via psql another time,
the item should be removed from the cache and the order request will produce a cache miss, followed by a SELECT against the item table in the database.
Summary
In this blog post we’ve explored how Debezium and change data capture can be employed to invalidate application-level caches after external data changes. Compared to manual cache invalidation, this approach works very reliably (by capturing changes directly from the database log, no events will be missed) and fast (cache eviction happens in near-realtime after the data changes).
As you have seen, not too much glue code is needed in order to implement this. While the shown implementation is somewhat specific to the entities of the example, it should be possible to implement the change event handler in a more generic fashion, so that it can handle a set of configured entity types (essentially, the database change listener would have to convert the primary key field(s) from the change events into the primary key type of the corresponding entities in a generic way). Also such generic implementation would have to provide the logic for obtaining the current transaction id for the most commonly used databases.
Please let us know whether you think this would be an interesting extension to have for Debezium and Hibernate ORM. For instance this could be a new module under the Debezium umbrella, and it could also be a very great project to work on, should you be interested in contributing to Debezium. If you got any thoughts on this idea, please post a comment below or come to our mailing list.
Many thanks to Guillaume Smet, Hans-Peter Grahsl and Jiri Pechanec for their feedback while writing this post!
About Debezium
Debezium is an open source distributed platform that turns your existing databases into event streams, so applications can see and respond almost instantly to each committed row-level change in the databases. Debezium is built on top of Kafka and provides Kafka Connect compatible connectors that monitor specific database management systems. Debezium records the history of data changes in Kafka logs, so your application can be stopped and restarted at any time and can easily consume all of the events it missed while it was not running, ensuring that all events are processed correctly and completely. Debezium is open source under the Apache License, Version 2.0.
Get involved
We hope you find Debezium interesting and useful, and want to give it a try. Follow us on Twitter @debezium, chat with us on Zulip, or join our mailing list to talk with the community. All of the code is open source on GitHub, so build the code locally and help us improve ours existing connectors and add even more connectors. If you find problems or have ideas how we can improve Debezium, please let us know or log an issue.