
This post originally appeared on the WePay Engineering blog.
Change data capture has been around for a while, but some recent developments in technology have given it new life. Notably, using Kafka as a backbone to stream your database data in realtime has become increasingly common.
If you’re wondering why you might want to stream database changes into Kafka, I highly suggest reading The Hardest Part About Microservices: Your Data. At WePay, we wanted to integrate our microservices and downstream datastores with each other, so every system could get access to the data that it needed. We use Kafka as our data integration layer, so we needed a way to get our database data into it.
Last year, Yelp’s engineering team published an excellent series of posts on their data pipeline. These included a discussion on how they stream MySQL data into Kafka. Their architecture involves a series of homegrown pieces of software to accomplish the task, notably schematizer and MySQL streamer. The write-up triggered a thoughtful post on Debezium’s blog about a proposed equivalent architecture using Kafka connect, Debezium, and Confluent’s schema registry. This proposed architecture is what we’ve been implementing at WePay, and this post describes how we leverage Debezium and Kafka connect to stream our MySQL databases into Kafka.
Architecture
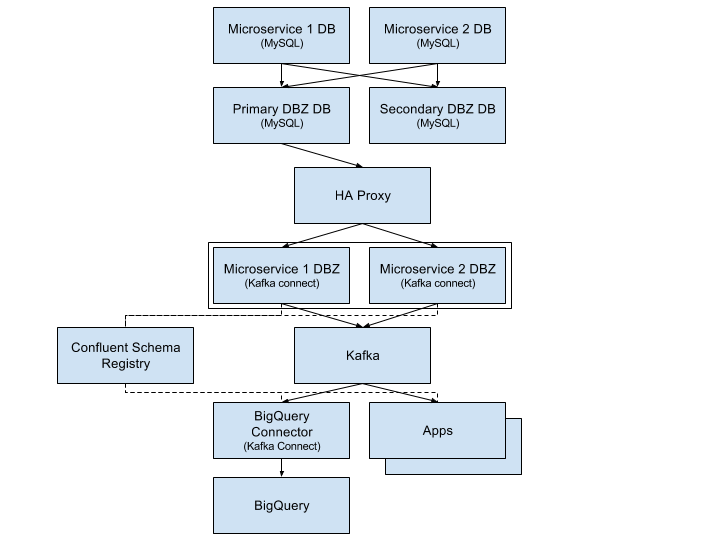
The flow of data starts with each microservice’s MySQL database. These databases run in Google Cloud as CloudSQL MySQL instances with GTIDs enabled. We’ve set up a downstream MySQL cluster specifically for Debezium. Each CloudSQL instance replicates its data into the Debezium cluster, which consists of two MySQL machines: a primary (active) server and secondary (passive) server. This single Debezium cluster is an operational trick to make it easier for us to operate Debezium. Rather than having Debezium connect to dozens of microservice databases directly, we can connect to just a single database. This also isolates Debezium from impacting the production OLTP workload that the master CloudSQL instances are handling.
We run one Debezium connector (in distributed mode on the Kafka connect framework) for each microservice database. Again, the goal here is isolation. Theoretically, we could run a single Debezium connector that produces messages for all databases (since all microservice databases are in the Debezium cluster). This approach would actually be more resource efficient since each Debezium connector has to read MySQL’s entire binlog anyway. We opted not to do this because we wanted to be able to bring Debezium connectors up and down, and configure them differently for each microservice DB.
The Debezium connectors feed the MySQL messages into Kafka (and add their schemas to the Confluent schema registry), where downstream systems can consume them. We use our Kafka connect BigQuery connector to load the MySQL data into BigQuery using BigQuery’s streaming API. This gives us a data warehouse in BigQuery that is usually less than 30 seconds behind the data that’s in production. Other microservices, stream processors, and data infrastructure consume the feeds as well.
Debezium
The remainder of this post will focus on Debezium (the DBZ boxes in the diagram above), and how we configure and operate it. Debezium works by connecting to MySQL and pretending to be a replica. MySQL sends its replication data to Debezium, thinking it’s actually funneling data to another downstream MySQL instance. Debezium then takes the data, converts the schemas from MySQL schemas to Kafka connect structures, and forwards them to Kafka.
Adding new databases
When a new microservice with a CloudSQL database comes online, we want to get that data into Kafka. The first step in the process is to load the data into the Debezium MySQL cluster. This involves several steps:
-
Take a MySQL dump of the data in the microservice DB.
-
Pause the secondary Debezium MySQL DB.
-
Load the MySQL dump into the secondary Debezium MySQL DB.
-
Reset
GTID_PURGEDparameter to include the GTID from the new DB dump. -
Unpause the secondary Debezium MySQL DB.
-
Update HA Proxy to point to the secondary, which now becomes the primary.
-
Follow steps 2-5 for the old primary instance (now secondary).
The actual commands that we run are:
# (1) Take a dump of the database we wish to add.
$ mydumper --host=123.123.123.123 --port=3306 --user=foo --password=********* -B log --trx-consistency-only --triggers --routines -o /mysqldata/new_db/ -c -L mydumper.log
# (2) Stop all replication on the secondary Debezium cluster.
$ mysql> STOP SLAVE for channel 'foo';
$ mysql> STOP SLAVE for channel 'bar';
$ mysql> STOP SLAVE for channel 'baz';
# Get the current GTID purged values from MySQL.
$ mysql> SHOW GLOBAL VARIABLES like '%gtid_purged%';
# (3) Load the dump of the database into the Debezium cluster.
$ myloader -d /mysqldata/new_db/ -s new_db
# (4) Clear out existing GTID_PURGED values so that we can overwrite it to include the GTID from the new dump file.
$ mysql> reset master;
# Set the new GTID_PURGED value, including the GTID_PURGED value from the MySQL dump file.
$ mysql> set global GTID_PURGED="f3a44d1a-11e6-44ba-bf12-040bab830af0:1-10752,c627b2bc-b36a-11e6-a886-42010af00790:1-9052,01261abc3-6ade-11e6-9647-42010af0044a:1-375342";
# (5) Start replication for the new DB.
$ mysql> CHANGE MASTER TO MASTER_HOST='123.123.123.123', MASTER_USER='REPLICATION_USER', MASTER_PASSWORD='REPLICATION_PASSWORD',MASTER_AUTO_POSITION=1 for CHANNEL 'new_db';
$ mysql> START SLAVE for channel 'new_db';
# Start replication for the DBs that we paused.
$ mysql> START SLAVE for channel 'foo';
$ mysql> START SLAVE for channel 'bar';
$ mysql> START SLAVE for channel 'baz';
# Repeat steps 2-5 on the old primary (now secondary).At the end of these steps, both the primary and secondary Debezium MySQL servers have the new database. Once finished, we can then add a new Debezium connector to the Kafka connect cluster. This connector will have configuration that looks roughly like this:
{
"name": "debezium-connector-microservice1",
"config": {
"name": "debezium-connector-microservice1",
"connector.class": "io.debezium.connector.mysql.MySqlConnector",
"tasks.max": "1",
"database.hostname": "dbz-mysql01",
"database.port": "3306",
"database.user": "user",
"database.password": "*******",
"database.server.id": "101",
"database.server.name": "db.debezium.microservice1",
"gtid.source.includes": "c34aeb9e-89ad-11e6-877b-42010a93af2d",
"database.whitelist": "microservice1_db",
"poll.interval.ms": "2",
"table.whitelist": "microservice1_db.table1,microservice1_db.table2",
"column.truncate.to.1024.chars" : "microservice1_db.table1.text_col",
"database.history.kafka.bootstrap.servers": "kafka01:9093,kafka02:9093,kafka03:9093",
"database.history.kafka.topic": "debezium.history.microservice1",
"database.ssl.truststore": "/certs/truststore",
"database.ssl.truststore.password": "*******",
"database.ssl.mode": "required",
"database.history.producer.security.protocol": "SSL",
"database.history.producer.ssl.truststore.location": "/certs/truststore",
"database.history.producer.ssl.truststore.password": "*******",
"database.history.consumer.security.protocol": "SSL",
"database.history.consumer.ssl.truststore.location": "/certs/truststore",
"database.history.consumer.ssl.truststore.password": "*******",
}
}The details on these configuration fields are located here.
The new connector will start up and begin snapshotting the database, since this is the first time it’s been started. Debezium’s snapshot implementation (see DBZ-31) uses an approach very similar to MySQL’s mysqldump tool. Once the snapshot is complete, Debezium will switch over to using MySQL’s binlog to receive all future database updates.
Kafka connect and Debezium work together to periodically commit Debezium’s location in the MySQL binlog described by a MySQL global transaction ID (GTID). When Debezium restarts, Kafka connect will give it the last committed MySQL GTID, and Debezium will pick up from there.
Note that commits only happen periodically, so Debezium might start up from a location in the log prior to the last row that it received. In such a case, you will observe duplicate messages in Debezium Kafka topic. Debezium writes messages to Kafka with an at-least-once messaging guarantee.
High availability
One of the difficulties we faced when we first began using Debezium was how to make it tolerant to machine failures (both the upstream MySQL server, and Debezium, itself). MySQL prior to version 5.6 modeled a replica’s location in its parent’s binlogs using a (binlog filename, file offset) tuple. The problem with this approach is that the binlog filenames are not the same between MySQL machines. This means that a replica reading from upstream MySQL machine 1 can’t easily fail over to MySQL machine 2. There is an entire ecosystem of tools (including MHA) to try and address this problem.
Starting with MySQL 5.6, MySQL introduced the concept of global transaction IDs. These GTIDs identify a specific location within the MySQL binlog across machines. This means that a consumer reading from a binlog on one MySQL server can switch over to the other, provided that both servers have the data available. This is how we run our systems. Both the CloudSQL instances and the Debezium MySQL cluster run with GTIDs enabled. The Debezium MySQL servers also have replication binlogs enabled so that binlogs exist for Debezium to read (replicas don’t normally have binlogs enabled by default). All of this enables Debezium to consume from the primary Debezium MySQL server, but switch over to the secondary (via HA Proxy) if there’s a failure.
If the machine that Debezium, itself, is running on fails, then the Kafka connect framework fails the connector over to another machine in the cluster. When the failover occurs, Debezium receives its last committed offset (GTID) from Kafka connect, and picks up where it left off (with the same caveat as above: you might see some duplicate messages due to periodic commit frequency).
An important configuration that needs to be called out is the gtid.source.includes field that we have set above. When we first set up the topology that’s described in the architecture section, we discovered that we could not fail over from the primary Debezium DB to the secondary DB even though they both were replicating exactly the same data. This is because, in addition to the GTIDs for the various upstream DBs that both primary and secondary machines are replicating, each machine has its own server UUID for its various MySQL databases (e.g. information_schema). The fact that these two servers have different UUIDs in them led MySQL to get confused when we triggered a failover, because Debezium’s GTID would include the server UUID for the primary server, which the secondary server didn’t know about. The fix was to filter out all UUIDs that we don’t care about from the GTID. Each Debezium connector filters out all server UUIDs except for the UUID for the microservice DB that it cares about. This allows the connector to fail from primary to secondary without issue. This issue is documented in detail on DBZ-129.
Schemas
Debezium’s message format includes both the "before" and "after" versions of a row. For inserts, the "before" is null. For deletes, the "after" is null. Updates have both the "before" and "after" fields filled out. The messages also include some server information such as the server ID that the message came from, the GTID of the message, the server timestamp, and so on.
{
"before": {
"id": 1004,
"first_name": "Anne",
"last_name": "Kretchmar",
"email": "annek@noanswer.org"
},
"after": {
"id": 1004,
"first_name": "Anne Marie",
"last_name": "Kretchmar",
"email": "annek@noanswer.org"
},
"source": {
"name": "mysql-server-1",
"server_id": 223344,
"ts_sec": 1465581,
"gtid": null,
"file": "mysql-bin.000003",
"pos": 484,
"row": 0,
"snapshot": null
},
"op": "u",
"ts_ms": 1465581029523
}The serialization format that Debezium sends to Kafka is configurable. We prefer Avro at WePay for its compact size, schema DDL, performance, and rich ecosystem. We’ve configured Kafka connect to use Confluent’s Avro encoder codec for Kafka. This encoder serializes messages to Avro, but also registers the schemas with Confluent’s schema registry.
If a MySQL table’s schema is changed, Debezium adapts to the change by updating the structure and schema of the "before" and "after" portions of its event messages. This will appear to the Avro encoder as a new schema, which it will register with the schema registry before the message is sent to Kafka. The registry runs full compatibility checks to make sure that downstream consumers don’t break due to a schema evolution.
Note that it’s still possible to make an incompatible change in the MySQL schema itself, which would break downstream consumers. We have not yet added automatic compatibility checks to MySQL table alters.
Future work
Monolithic database
In addition to our microservices, we have a legacy monolithic database that’s much larger than our microservice databases. We’re in the process of upgrading this cluster to run with GTIDs enabled. Once this is done, we plan to replicate this cluster into Kafka with Debezium as well.
Large table snapshots
We’re lucky that all of our microservice databases are of relatively manageable size. Our monolithic database has some tables that are much larger. We have yet to test Debezium with very large tables, so it’s unclear if any tuning or patches will be required in order to snapshot these tables on the initial Debezium load. We have heard community reports that larger tables (6 billion+ rows) do work, provided that the configuration exposed in DBZ-152 is set. This is work we’re planning to do shortly.
More monitoring
Kafka connect doesn’t currently make it easy to expose metrics through the Kafka metrics framework. As a result, there are very few metrics available from the Kafka connect framework. Debezium does expose metrics via JMX (see DBZ-134), but we aren’t exposing them to our metrics system currently. We do monitor the system, but when things go wrong, it can be difficult to determine what’s going on. KAFKA-2376 is the open JIRA that’s meant to address the underlying Kafka connect issue.
More databases
As we add more microservice databases, we’ll begin to put pressure on the two Debezium MySQL servers that we have. Eventually, we plan to split the single Debezium cluster that we have into more than one, with some microservices replicating only to one cluster, and the rest replicating to others.
Unify compatibility checks
As I mentioned in the schema section, above, the Confluent schema registry runs schema compatibility checks out of the box right now. This makes it very easy for us to prevent backward and forward incompatible changes from making their way into Kafka. We don’t currently have an equivalent check at the MySQL layer. This is a problem because it means it’s possible for a DBA to make incompatible changes at the MySQL layer. Debezium will then fail when trying to produce the new messages into Kafka. We need to make sure this can’t happen by adding equivalent checks at the MySQL layer. DBZ-70 discusses this more.
Automatic topic configuration
We currently run Kafka with topic auto-create enabled with a default of 6 partitions, and time-based/size-based retention. This configuration doesn’t make much sense for Debezium topics. At the very least, they should be using log-compaction as their retention. We plan to write a script that looks for mis-configured Debezium topics, and updates them to appropriate retention settings.
Conclusion
We’ve been running Debezium in production for the past 8 months. Initially, we ran it dark, and then enabled it for the realtime BigQuery pipeline shown in the architecture diagram above. Recently, we’ve begun consuming the messages in microservices and stream processing systems. We look forward to adding more data to the pipeline, and addressing some of the issues that were raised in the Future work section.
A special thanks to Randall Hauch, who has been invaluable in addressing a number of bug fixes and feature requests.
About Debezium
Debezium is an open source distributed platform that turns your existing databases into event streams, so applications can see and respond almost instantly to each committed row-level change in the databases. Debezium is built on top of Kafka and provides Kafka Connect compatible connectors that monitor specific database management systems. Debezium records the history of data changes in Kafka logs, so your application can be stopped and restarted at any time and can easily consume all of the events it missed while it was not running, ensuring that all events are processed correctly and completely. Debezium is open source under the Apache License, Version 2.0.
Get involved
We hope you find Debezium interesting and useful, and want to give it a try. Follow us on Twitter @debezium, chat with us on Zulip, or join our mailing list to talk with the community. All of the code is open source on GitHub, so build the code locally and help us improve ours existing connectors and add even more connectors. If you find problems or have ideas how we can improve Debezium, please let us know or log an issue.